こんにちは。MySQLは秋の季語とする一派が世に存在していることを知り、私もMySQLに関わる記事を書いてみようと筆を取ることにしました。
さて、リレーショナルデータベースをバックエンドとするWebアプリケーション開発において、特定の条件に合致するレコードがN件存在するかどうかを確認するロジックは頻出といえます。プログラマとして一度は書いたことがあるのではないでしょうか?
この記事ではそのような件数カウントを行うためのクエリが引き起こした性能劣化と、その改善アプローチについて紹介していきます。
なお、本記事の内容はMySQLを前提としており、アプリケーションコードの例はRuby on Railsを用いますが特別な前提知識は必要ありません。コードの雰囲気だけ感じ取っていただければと思います。
ありがちなコード if query.count == n の問題
冒頭で述べた通り、特定の条件に合致するレコードがN件存在するかどうかを確認するロジックを実装する機会がしばしばあるとしましょう。このロジックを実装するとき、最もシンプルに思いつくアプローチは以下のような手順です。
select count(*) from table where ...のようなSQLを用いて件数をカウントする- アプリケーション側で件数を比較して条件判定する
Railsのコードで表現するならばこんなコードになるでしょう。我々のコードベースでもよく見た風景です*1。
# なんらかの複雑な条件を満たすレコードをカウントして条件判定に使う # e.g. 限定クーポンで特定商品をキャンペーン期間内に購入したか、みたいな if current_user.payments.where(...).count == 1 # 初回の購入であれば何らかのボーナスをあげる end
ここで発行されるSQLはこんな感じです。
select count(*) from payments where payments.user_id = 1 and -- なんらかの複雑な条件が続いていく ;
一見シンプルで何の変哲もない方法ですが、パフォーマンスの観点においては常に最適なコードやクエリとは言えない...という話をしていきます。
全件カウントの落とし穴
select count(*) from table where ... クエリは、条件に合致するすべてのレコードを数え上げます。上記のコード例でいえば、1件だけ存在するかどうかを確認したいだけなのにすべてを数え上げる余分なコストが発生することになります。
とりわけ、適切なインデックスがない場合や、大規模なテーブルで条件に合致するレコードが広範囲に分散している場合、このクエリは想定以上に時間を要する可能性があります。
我々の遭遇したケース
我々が遭遇したのもまさにそのようなケースでした。数千万件のレコードがあるテーブルに対し、条件に合致するレコードが1件あるかどうかを確認すればよいところで、全件を数え上げるクエリが実行されていました。
このクエリが主な原因となり、とあるWeb APIのレスポンスタイムが悪化していることが判明したことで改善に乗り出すことになりました。
原因の考察
ここからは我々のケースではなぜ count クエリの性能が劣化していたのか、原因の考察に入っていきましょう。
適切なインデックスがなくテーブルアクセスが発生
問題のSQLはカウントクエリなので、検索条件をすべてカバーできるインデックスがあればカバリングインデックスによりテーブルアクセスを抑制することができます。しかし、今回のケースでは複雑な条件をカバーするためのインデックスが作成されておらず、テーブルアクセスが常に発生するクエリになっていました。
テーブルアクセスによりディスクI/Oが発生
今回のクエリでアクセスするテーブルには数千万件のレコードがあるため、すべてのデータがバッファプールに保持されていることはまずありえない状況でした。必要なデータがバッファプール内に存在する可能性が低い状況でテーブルアクセスが発生すると、必要なデータを読み出すためのディスクI/Oが発生します。
加えて、性能劣化に直面したクエリは、同テーブルにおいて広範囲に分散した関連レコードを持っていたことが確認されました。このことから、カウントクエリが低いパフォーマンスを叩き出しているときはテーブルアクセスに伴うディスクI/Oが複数回にわたり発生しているのではないかと疑いました。
本番環境相当のデータを用意して実験したところ、初回のクエリ実行時には数秒かかり、2回目以降は数十ミリ秒以下で終了することが確認されたためこの仮説が正しいだろうと判断して改善を試みました。(より良い仮説検証の方法をご存知の方がいればぜひ教えてください)
改善に向けて検討したアプローチ
さて、原因であろうポイントを説明したので、ここからは改善に向けて検討したアプローチと、実際に選択したアプローチについて述べていきます。
インデックスの追加
すぐに検討した改善策はインデックスの追加です。
検索条件に使用されるカラムに適切なインデックスを設定することで、クエリのパフォーマンスを大幅に向上させられないかと考えました。特に、カバリングインデックスを使用できればデータページへのアクセスを抑えられます。
しかし、現状のテーブル構成やデータ分布からは効率的なインデックスを作成することが難しい状況でした。効率化のためにはテーブルのスキーマ変更も検討せねばならず、影響範囲やマイグレーションに対応する工数も必要でした。この案はお見送りです。*2
アプリケーションのロジックの見直し
アプリケーションのロジックは数年前に実装されていたものなので「N件以上存在するか」という条件チェックが本当に必要かを再考しました。
再考によりクエリを簡素にできる余地があればよかったのですが...今回は変更ができなかったためこの案もお見送りとなりました。
選ばれたのは... LIMIT 句を活用して最小限の走査に抑えるアプローチ
インデックスの追加やスキーマの変更、アプリケーションのロジックの見直しが難しかったため、今回は LIMIT 句を活用して最小限のテーブルアクセスに抑えるアプローチを取りました。
「1件だけ存在すること」を確認したいのであれば LIMIT 2 をつけたクエリを発行します。これにより、3件目以降を数え上げるためのテーブルアクセスを抑制できます。
select count(*) from payments where payments.user_id = 1 and -- なんらかの複雑な条件が続いていく limit 2 -- 2件以上のレコードがあるとわかったら走査を終了する ;
アプリケーションとしては、クエリの結果が1件であれば「1件だけ存在する」と判定できるというわけです。
なんだかすごく当たり前のことを言っていますね。ORMを用いた query.count == 1 があまりに簡易で読み書きしやすいので忘れがちなんですかねぇ。
Rails の ActiveRecord::Relation#one? を使う
Railsではこのための便利なメソッド、ActiveRecord::Relation#one?*3 が用意されています。これを使うと冒頭のコードは以下のように表現できます。
- if current_user.payments.where(...).count == 1 + if current_user.payments.where(...).one? # 初回の購入なので何らかのボーナスをあげる end
-- one? メソッドが発行するクエリイメージ select count(*) from ( select 1 as one from payments where payments.user_id = 1 and -- なんらかの複雑な条件が続いていく limit 2 ) subquery_for_count ;
one? メソッドの実装では、まさに LIMIT 2 をつけたクエリを発行して得られた件数の比較をしています。興味があれば見てみてください。
https://github.com/rails/rails/blob/v7.2.1/activerecord/lib/active_record/relation.rb#L397-L403
もし「1件存在すること」でなく「N件存在すること」を確認したいのであれば、同等のことを .limit(n+1) を用いて表現できます。
- if current_user.payments.where(...).count == 1 + if current_user.payments.where(...).limit(n+1).count == n # N回目の購入なので何らかのボーナスをあげるなど end
改善結果
我々が遭遇したパフォーマンス問題の元凶となったコードを .count == 1 から .one? に変更してみたところ... デプロイ直後から明らかな差が見られました。
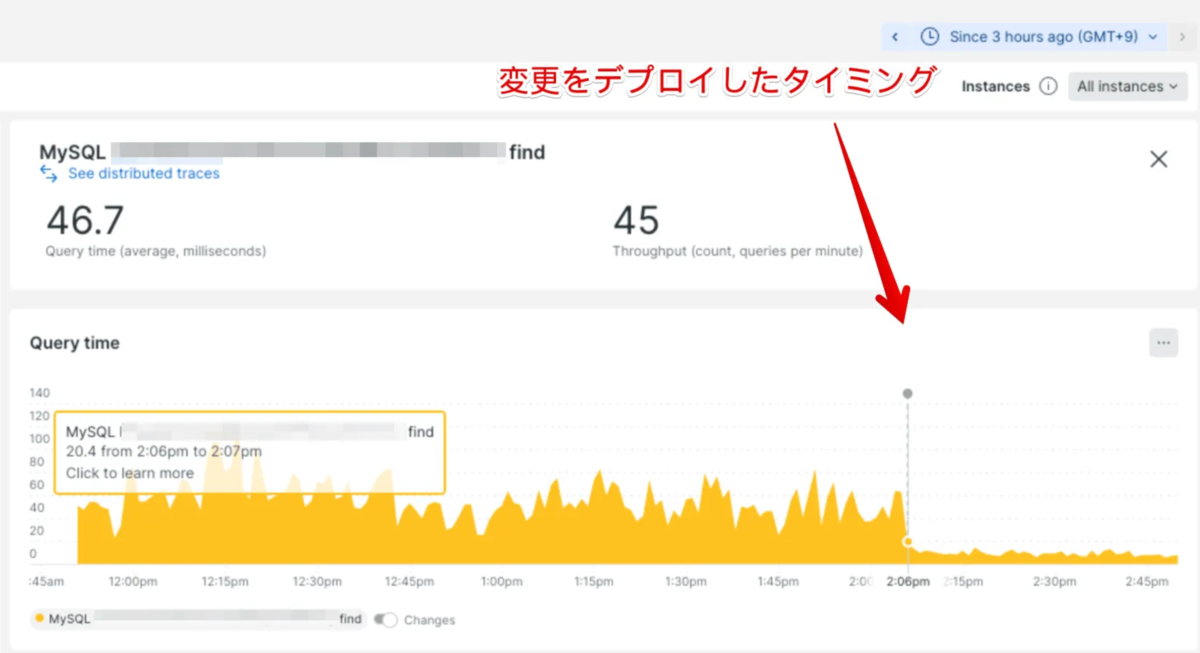
この画像では問題のクエリの平均実行時間を表しており、縦の点線(デプロイメントマーカー)を境に1/3以下に改善していることがわかります。
また、このクエリを実行しているWeb APIの99パーセンタイル値も前日同時刻比で数十%の改善が見られました。青の点線がbefore、青の実線がafterです。
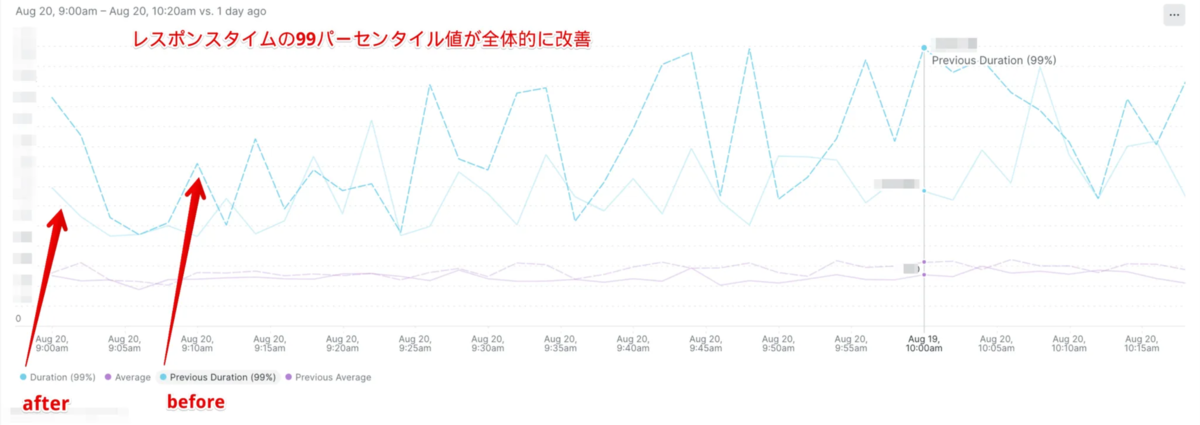
実数を伏せていますが雰囲気が伝わればと思います。
すべてのケースで有効なアプローチではない
最後に1点だけ注意をお伝えすると、LIMIT 句を使うアプローチは今回起きていたようなテーブルアクセスを100%抑制できるものではありません。条件に合致する行が0件または1件の場合は結局すべて走査してしまいます。
幸いにも今回の我々のユースケースでは問題のクエリの緩和策としては有効でした。
- 2件以上存在する場合が大半を占めていた
- 1件のデータしか持たないのはINSERT直後にカウントクエリが発行されるケースだったため、そのデータがバッファプールに保持されている可能性が高かった
- 0件のときにカウントクエリが発行されることはなかった
終わりに
本記事では特定の条件に合致するレコードがN件存在するかどうかを確認する頻出コード、クエリで起きた性能劣化と改善アプローチについて紹介しました。
今回のような事象をそもそも起こさないためには「将来のデータ増加を見越してスキーマ設計すべき」「インデックスをちゃんと設計・作成すべき」という真っ当な指摘もあるかと思います。
しかしながら、すでに起きてしまっている目前の問題への緩和策が必要なシーンもあります。今回紹介した LIMIT 句を用いたテーブルアクセスの抑制もそのための一手段として、パフォーマンス問題に悩む方の助けになれば幸いです。
本記事はスマートバンクの @ohbarye が執筆しました。
スマートバンクではパフォーマンス改善に関心のあるサーバーサイドエンジニアを募集しております!
*1:今回記述した問題があったため、今ではほとんど消えました
*2:時間をかけて取り組めるならもちろん検討する価値はあります
*3:https://api.rubyonrails.org/classes/ActiveRecord/Relation.html#method-i-one-3F