こんにちは。株式会社スマートバンクのサーバーサイドエンジニアをやっております![]() id:moznionです。
id:moznionです。
すっかり秋めいてきましたね。秋といえばMySQL*1、ということで今回は先日解消した「MySQLのロックに起因するブロックタイムアウト」のトラブルシューティングついて記していきたいと思います。
事の発端
ある時を境にSentryに ActiveRecord::LockWaitTimeout というエラーがしばしば報告されるようになっていました。

Mysql2::Error::TimeoutError: Lock wait timeout exceeded という文言から、MySQL上でロックを取っている他のクエリにブロックされ、そのブロックが長時間に渡ったため自クエリがタイムアウトしてabortしてしまっているという状況のようです。
このabortしてしまったクエリについては再度実行すれば普通に通る類のものではあるのですが、当然ユーザーからの見え方としては「長時間待たされた上に失敗」した上に「再度リクエストが必要」という劣悪な体験となるため解消すべきです。というわけで直していきましょう。
事前調査
Sentryに報告されてくる「同種のエラー」を分析したところ、同僚のohbaryeさんが以下の発生傾向を発見しました。

UPDATEのオペレーションでブロックされているということ、そして発生する時間が限定的であることからなんらか定期的に実行されているバッチか何かが原因であることが推察されました。
本調査
というわけでこの時間帯で狙い撃ち、どのクエリがロックを取っているか (つまり原因になっているか) を調査することとしました。
ロックの検出については先行事例がいくつかあり、主に以下を参考にしました:
- https://blog.kinto-technologies.com/posts/2024-03-05-aurora-mysql-stats-collector-for-blocking/
- https://gihyo.jp/dev/serial/01/mysql-road-construction-news/0148
株式会社スマートバンクでもAmazon Aurora MySQLを利用しているため、KINTOさんが構築されているような仕組みをそのまま再現しても良かったのですが、調査したい対象・時刻ウインドウが限定的であったことと小さく始めたいというモチベーションから「ロックの検出及びその原因となっているクエリを検出するバッチ」を毎日定時で一定時間だけ動作するタスクとして構築・実現しました。
InnoDBレベルでのトランザクションのロックおよびその原因の検出
information_schema.INNODB_TRX テーブルを参照することでInnoDB上で現在実行中または保留中のトランザクションに関するリアルタイムな情報を取得することができます。
INNODB_TRXテーブルには、InnoDB内で現在実行されているすべてのトランザクションに関する情報が表示されます。これには、トランザクションがロックを待機しているかどうか、トランザクションの開始時、トランザクションが実行されている SQL ステートメント (ある場合) などが含まれます。 https://dev.mysql.com/doc/refman/8.0/ja/information-schema-innodb-trx-table.html
このテーブルに対して
SELECT 1 FROM information_schema.INNODB_TRX WHERE timestampdiff(second, `TRX_WAIT_STARTED`, now()) >= 1 LIMIT 1
というクエリを実行することで、TRX_WAIT_STARTED (トランザクション待ちが開始された時刻) カラムについて、1秒以上経過したエントリ (つまり1秒以上待ち状態のトランザクション) が存在していた場合にInnoDBのブロックが生じていると見做して検出することができます。
ちなみにですが、この時 TRX_STATE カラムは必ずしも LOCK WAIT にはなりません。なぜなら実行タイミングにおいてロック待ち状態が解消されているクエリの可能性もあるためです (LOCK WAIT から RUNNING に遷移したクエリであっても TRX_WAIT_STARTED が長ければそれはかつてブロック待ちだったクエリと見做せるため)。
参考として TRX_STATE の状態遷移図を記載します:
stateDiagram-v2 [初期状態] --> RUNNING RUNNING --> LOCK_WAIT: ロック待ち発生\n(ここからTRX_WAIT_STARTED) LOCK_WAIT --> RUNNING: ロック取得 RUNNING --> ROLLING_BACK: ロールバック開始 ROLLING_BACK --> [トランザクション終了]: ロールバック完了 RUNNING --> COMMITTING: コミット開始 COMMITTING --> [トランザクション終了]: コミット完了
ロックを検出した際に以下のクエリを発行すると、そのトランザクションをブロックしているクエリの詳細を取得することができます:
SELECT * FROM performance_schema.events_statements_history WHERE THREAD_ID IN (SELECT BLOCKING_THREAD_ID FROM performance_schema.data_lock_waits) ORDER BY EVENT_ID DESC LIMIT 10 # LIMITの件数については適宜調整してください
performance_schema.data_lock_waits テーブルにはInnoDBレベルでのロック待機状態のクエリのメタデータがストアされています。
このテーブルからクエリをブロックしているクエリを実行しているスレッドIDすなわちBLOCKING_THREAD_ID カラムの値を使用してperformance_schema.events_statements_history テーブルを引くことで原因となるブロックしているクエリを取得することができます。
ちなみに: performance_schema.events_statements_current テーブルを使うと「そのスレッドが実行した直近のクエリ」しか取得できず、適切なブロック要因となっているクエリを取れない可能性があるので、実行クエリを履歴として保持している performance_schema.events_statements_history を利用しています。
諸注意としてはperformance_schema.events_statements_history テーブルは有効化されていないと引くことができないので有効にする必要があります *2 。また、performance_schema.events_statements_history が保持するクエリの件数は performance_schema_events_statements_history_size によって設定されます。この値が大きければ大きいほど保持する件数が増えるので真のブロック要因となっているクエリを参照できる可能性が高まりますが、そのぶんメモリ消費量も増大するので注意が必要です。
see also: https://dev.mysql.com/doc/refman/8.0/ja/performance-schema-events-statements-history-table.html
メタデータロックおよびその原因の検出
メタデータロックはテーブルやスキーマなどの構造が変更される(例: ALTER TABLE や DROP TABLE の実行)際に競合が発生しないようにするために使用されます。
MySQL では、メタデータロックを使用して、データベースオブジェクトへの同時アクセスを管理し、データの一貫性を確保します。 メタデータのロックは、テーブルのみでなく、スキーマ、ストアドプログラム (プロシージャ、ファンクション、トリガー、スケジュール済イベント)、テーブルスペース、GET_LOCK() 関数で取得されたユーザーロック (セクション12.15「ロック関数」 を参照)、および セクション5.6.8.1「ロックサービス」 で説明されているロックサービスで取得されたロックにも適用されます。 https://dev.mysql.com/doc/refman/8.0/ja/metadata-locking.html
このメタデータロックに関しては performance_schema.metadata_locks パフォーマンステーブル内に lock_status カラムの値が PENDING のレコードの有無によってロックが取られているかどうかを判断することができます。
SELECT 1 FROM performance_schema.metadata_locks WHERE lock_status = 'PENDING' LIMIT 1
このクエリのresult setが得られた場合、メタデータロックが発生していると見做すことができます。
そしてこのメタデータロックの原因となっているクエリの詳細は以下のようなクエリによって取得することができます:
SELECT * FROM performance_schema.events_statements_history WHERE THREAD_ID IN (SELECT blocking_thread_id FROM sys.schema_table_lock_waits) ORDER BY EVENT_ID DESC LIMIT 10 # LIMITの件数については適宜調整してください
sys.schema_table_lock_waits ビューにはロック待ち (ブロック状態) のクエリのメタデータがストアされており、そのロック待ちクエリをブロックしているスレッドのID (blocking_thread_id) を使ってperformance_schema.events_statements_history を引くことでブロック源となっているクエリを取得できます。
(performance_schema.events_statements_historyについてはトランザクションのロックと同様なので説明は割愛します)
トラブルシューティング観点では、同じ時間帯に定期的に実行されるようなものでもないためこのメタデータロックが原因となっているとは考えにくかったのですが念の為にこの検出ロジックも併せて仕込んでいました。
運用
株式会社スマートバンクでは主としてRuby on Railsを用いて開発しているため、こういった「ロックの検出」および「ロックの原因となっているクエリを検出」するためのクエリを定期実行 (例えば10秒おきに実行する) するRakeタスクを作成し、それをAirflowのDAGとして呼び出せるようにして運用しました。
問題が発生している時間帯に実行できるよう、Airflow上で毎日午後10時から2時間このRakeタスクを起動するように定期実行のスケジュールを組み、実行に際してはこのタスクはAmazon ECS Fargateのワンショットタスクとして扱われるように設定しました。
前準備
「本調査」にも書いた通り、ロック原因となっているクエリを検出するためにはMySQLの設定を調整しなくてはなりません。具体的には
performance_schema.setup_consumersテーブルでevents_statements_historyを有効にするperformance_schema_events_statements_history_sizeを適切な値に設定する
ということをする必要があります。これは適宜やりましょう。
前述の通り performance_schema_events_statements_history_size を大きな値にするとMySQLのメモリ消費量が増大する可能性があるので注意してください。
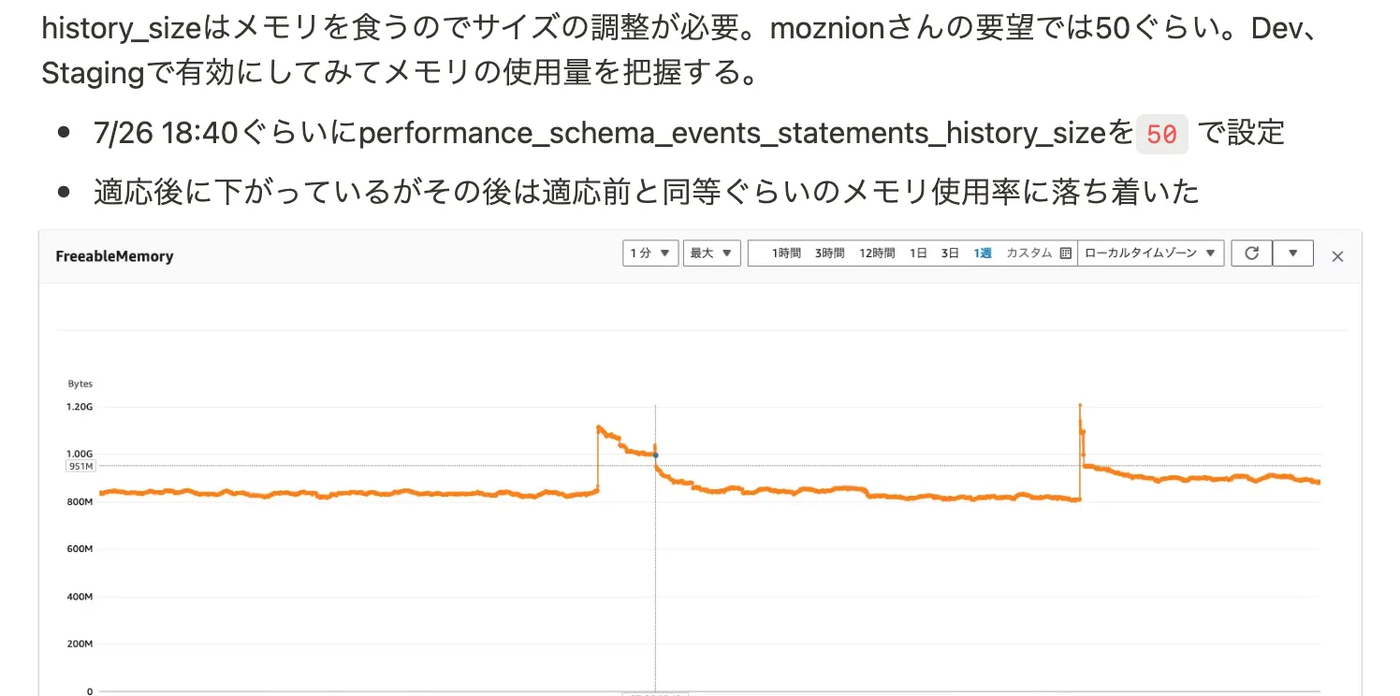

また、Rakeタスクによる検出のためのクエリは数秒おきに発行されるためパフォーマンスへの影響にも注意を払う必要があります。今回はproduction環境に投入する前に開発用環境およびステージング環境に対して先んじて適用をし、性能へのインパクトを計測した上で問題が無いことを確認してからproduction環境へと適用しました。
検出
実行しているタスクがロック原因となるクエリを検出した際はSlackへその旨を通知するようにしました。
センシティヴな情報が含まれている可能性がある実クエリをSlackに通知してしまうと後々良くないことが起きそうだということで、Slackには「ロックを検出しました」という情報だけを通知するに留め、ロック原因となっている実クエリについてはセキュアなログストレージに保存するようにしました。通知を受け取った開発者はそのログストレージを参照することで原因となっているクエリを調査できるという形です。
そして解決へ…
ロック原因となっているクエリを確認したところ、とあるバッチ内で数千件〜レベルのレコードのUPDATEに対して1つの巨大transactionが張られていることがわかりました。そりゃあ長い時間ロック取られますね。コードの内容的に一枚岩の巨大トランザクションにしなくても良かったので、トランザクションを各レコードレベルにバラしたところ無事問題が解決しました。めでたい。
問題が解決して以降はこのロック検出タスクは無効にして動かしていないのですが、今後同様の問題が発生した時にはAirflow経由でサクッと再度有効にできるのでなかなか便利なのではないかと思っております。
まとめ
- InnoDBレベルでのロック検出およびロック原因となっているクエリの取得方法
- MySQLのメタデータロックの検出およびロック原因となっているクエリの取得方法
- これらのロック検出クエリをn秒おきに定期実行する処理をRakeタスク化し、そのバッチをAirflowでスケジュールしてAmazon ECS Fargateのワンショットタスクとして定期実行する方法
以上を紹介しました。これによりロック原因となっているクエリを検出して問題解決まで持っていくことができました。よかったですね。
余談
ロック原因となっているクエリを検出したのは良いのですが、 SQL_TEXT が長すぎると途中で切られてしまいトラブルシューティングが難しかったという苦難がありました。Active Recordのクエリコメント (実際のコード中のどこでクエリが生成されているか、などの情報) を有効にしていてもクエリが長いと切られてしまってどこが原因なのかがさっぱりわからないのですよね。
MySQL側で適切に performance_schema_max_sql_text_length を設定しないとこのあたりが途中で切られてしまって上手くいかないので良い感じで設定しましょう。今回は設定をイジらずに途中で切れたクエリを強く睨み、念力によって解決を図りました*3。大変ですね。
*1:https://x.com/moznion/status/1833403444956434795
*2:SELECT * FROM performance_schema.setup_consumers WHERE NAME = 'events_statements_history' によって有効かどうかを確認できます
*3:結果中にクエリダイジェストは存在するのでそういったところからアタリを付けることは可能です