この記事は株式会社スマートバンク Advent Calendar 2024 6日目の記事です。
昨日は kassy さんの「成長するスタートアップ労務の醍醐味と挑戦をUXリサーチャーが聞いてみた!」という記事でした。
はじめに
サーバーサイドエンジニアの mokuo です。普段は、カード決済やあとばらいチャージに関連する機能の開発や運用を行っております。
本日は、サーバーサイドエンジニア向けの記事になります。
本記事でお話しすること
システムには断続的に行われる一連の処理、というものがあります。この中で非同期処理を行うこともあるでしょう。
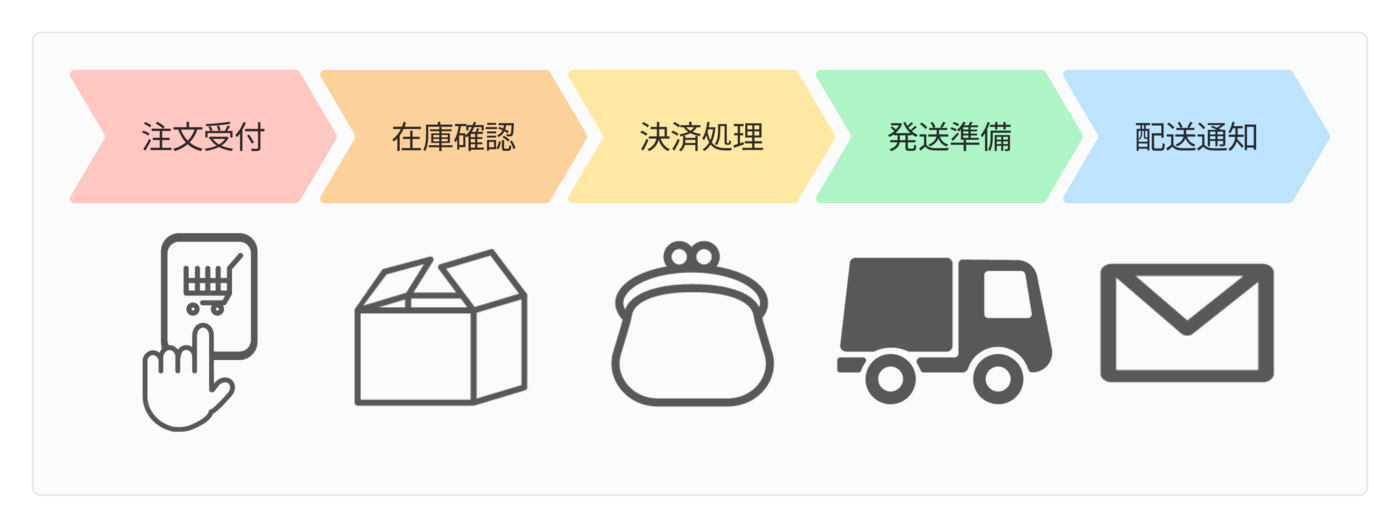
このような機能を開発・運用していると、以下のような課題に直面することがあります。
- 処理の流れが把握し辛い
- 変更を行うのが困難
- データの整合性を担保するのが難しい
しかし、適切に設計を行うことで、これらの課題を回避することができます。本記事では、上記の課題を解消するアーキテクチャのパターンを紹介します。
💽 イベントを正しく保存する
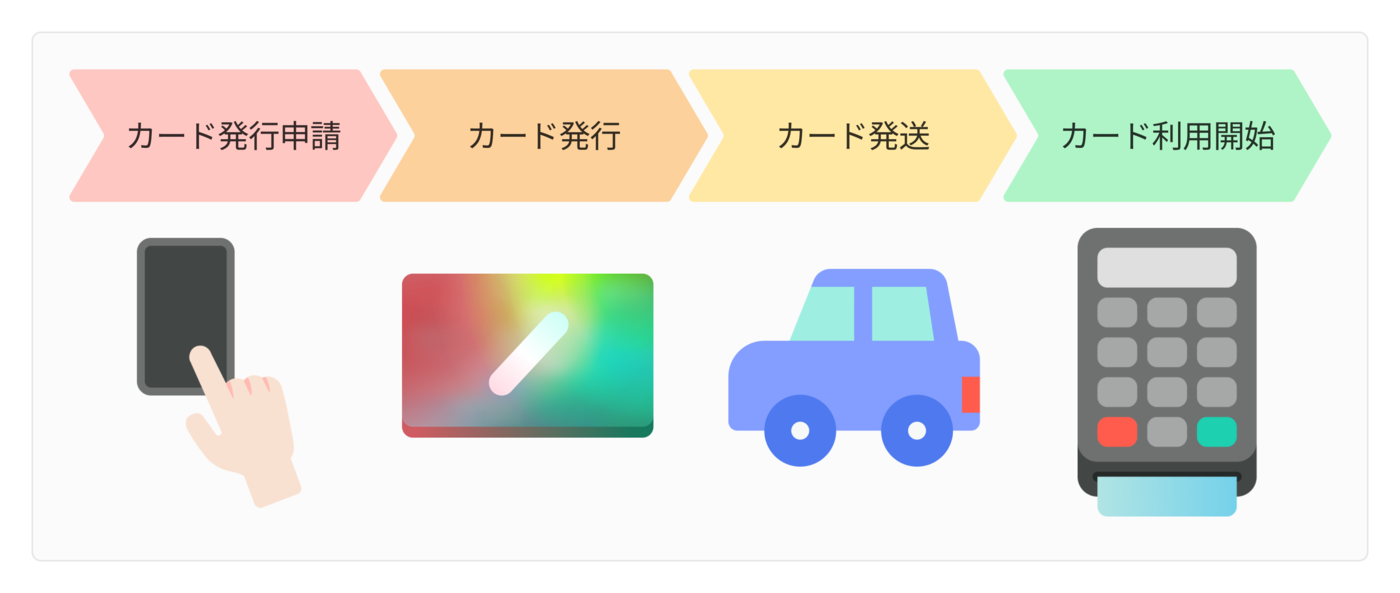
💳 例) B/43 アプリのカード発行フロー
本記事では、弊社 B/43 アプリのカード発行フローを例に話をしていきたいと思います。*1
🎨 モデリング
同期処理においても非同期処理においても、まずはイベント(出来事)を正しくモデリングし、データベースに保存できるようにしましょう。

イベントのモデルが持つデータは、大きく4種類になります。
- イベントの識別子(ID など)
- 関連するモデルのID(ユーザーやカードなど)
- その他、関連するデータ(カード名義など)
- イベントが発生した日時
日時カラムでソートすれば、ユーザーがカード発行申請を行ってから利用開始するまでの流れを追うことができるようになります。
モデリングの手順については、手前味噌で恐縮ですが、以下の資料も参考にしていただけますと幸いです。
👬 関連するイベントのIDを持たせる
上記のモデルに、さらに関連するイベントの ID を持たせると、イベント同士の関連が分かりやすくなります。
ただし、ID の持たせ方にはいくつかのパターンがあります。*2
パターン①: 1つ前のイベントのIDを持たせる
カード発行イベントであれば、カード発行申請イベントの ID を持たせます。
これにより、どのイベントの後に発生したイベントであるか、明確になります。

ただし、一連のイベントを全て確認するには、一つずつ ID を辿っていく必要があり、イベントの数が増えればコストがかかる処理になります。
パターン②: 最初のイベントのIDを持たせる
全てのイベントに、カード発行申請ID を持たせます。
これにより、特定のカード発行申請の後に発生したイベントを一気に引いてくることができます。

ただし、前後のイベントを引いてくることはできません。
パターン③: ツリー構造で持たせる
ID をツリー状のデータとして持たせることもできます。
カード発行申請IDカード発行申請ID/カード発行IDカード発行申請ID/カード発行ID/カード発送IDカード発行申請ID/カード発行ID/カード発送ID/カード利用開始ID
書籍『SQL アンチパターン』で経路列挙モデルとして紹介されている手法です。
Ruby では ancestry という gem があって、簡単に導入することができます。

ただし、経路列挙モデルをサポートするライブラリがない言語では、実装にコストがかかるかもしれません。
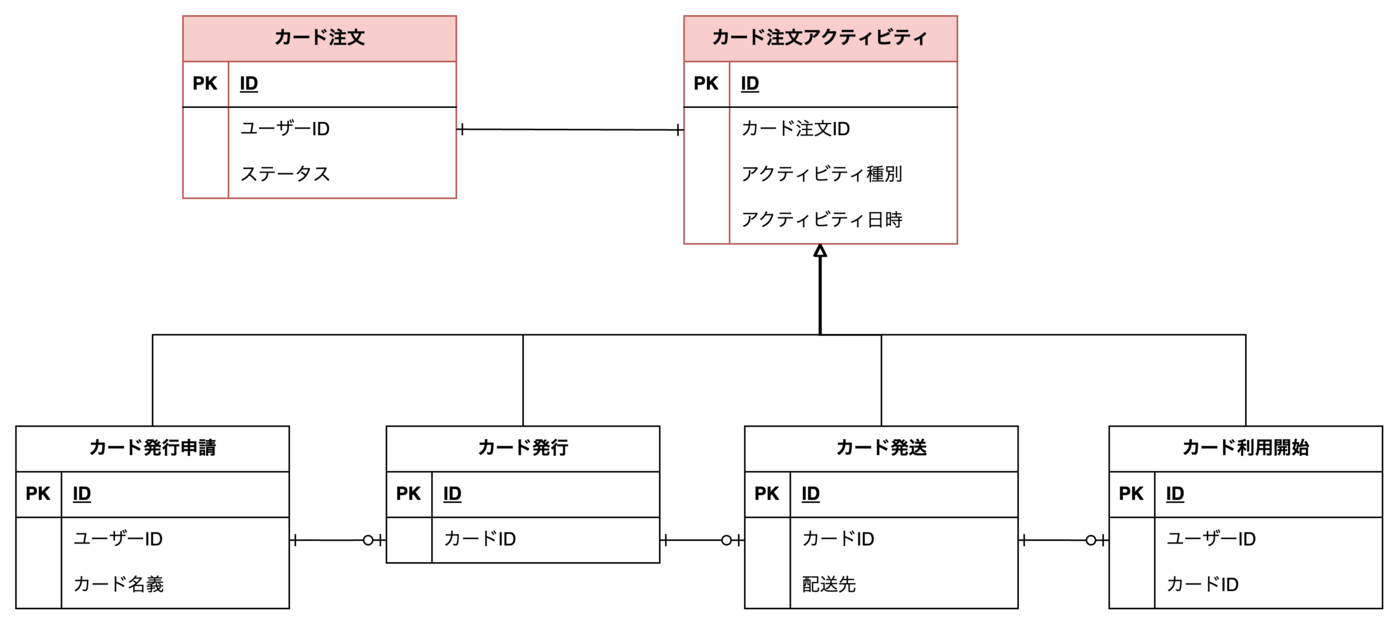
パターン④: ロングタームイベント
『WEB+DB PRESS Vol.130』の特集1 第4章で紹介されているパターンです。
ユーザーからカード発行申請を受け付けた後に、現在の最新のステータスを知りたい、ということはよくあるユースケースでしょう。その場合に、上記の3パターンでも最新のイベントをクエリで引くことは可能ですが、性能面でボトルネックになる可能性があります。
そこで、各イベントのスーパータイプとして カード注文アクティビティ モデルを用意し、それに紐づく カード注文 モデルを定義します。これをロングタームイベントと呼びます。
📝 パターン①~④のメリット/デメリット
| 前後のイベントを引く | 全イベントを引く | 最新ステータスを知る | 実装コスト | |
|---|---|---|---|---|
| ① 先行イベント | ⭕ | ❌ | ❌ | ⭕ |
| ② 親イベント | ❌ | ⭕ | 🔺 | ⭕ |
| ③ ツリー構造 | ⭕ | ⭕ | 🔺 | 🔺 |
| ④ ロングターム | ❌ | ⭕ | ⭕ | 🔺 |
個人的には、まずは①を検討して、イベントの数が多くて最新のステータスが分かりにくければ、①と④を組み合わせる(④でさらに、先行イベントIDを持たせる)のが良さそうな気がしています。試したことはないです。
❌ NGパターン: 全部盛りモデル

複数のイベントの情報が1つのモデルに入ってしまっています。カラムの更新タイミングなどにルールがあるのであれば、アプリケーションのレイヤーで制御を入れる必要があるでしょう。
データベースのレイヤーで解決できる複雑さをアプリケーションのレイヤーに持ち込まない、ということは大切な考え方です。
イベント(出来事)は、1度起きると更新されることはありません。1つのテーブルに1つのイベントとすることで、データのまとまりがはっきりと分かるようになるでしょう。
♻️ 非同期処理においてデータ整合性を保つ
💬 非同期メッセージング
非同期メッセージングを導入する目的は、主に以下2つを向上させることです。
- 可用性
- パフォーマンス
書籍『ソフトウェアアーキテクチャの基礎』では、可用性を以下のように定義しています。
システムがどれくらいの期間利用できるか(24 時間 365 日稼働する場合には、障害が発生 した場合に迅速にシステムを稼働できるようにするための措置が必要となる)。
連携システムと同期通信を行っている場合、ユーザーは通信が終わるまで待たなくてはいけません。また、連携システムで障害が発生した場合、依存する機能は停止してしまいます。
非同期通信を行うことで、ユーザーからのリクエストを受け付けてレスポンスを返してしまい、裏で連携システムとの通信を行うことが可能です。これにより、可用性とパフォーマンスの向上が見込まれます。
📤 データベースとメッセージキューの整合性を保つ Transactional outbox パターン
通常、キューへのメッセージ送信をデータベースのトランザクション内で行うことはできないため、何らかの方法で整合性を担保する必要があります。*3
書籍『マイクロサービスパターン』では、非同期メッセージとDB トランザクションの間で整合性を取る方法として、 Transactional outbox パターンが紹介されています。
※『3.3 非同期メッセージングパターンを使った通信 3.3.7 トランザクショナルメッセージング』より
一時メッセージキューとしてデータベースに OUTBOX というテーブルを持ち、トランザクション内でこのテーブルにレコードを挿入します。

このテーブルからパブリッシュされていないメッセージを取り出してメッセージキューに送信する方法として、さらに2つのパターンが紹介されています。
パターン①: Polling publisher
上記の OUTBOX テーブルに対して、定期的にポーリング(クエリ)して、キューにメッセージを送信した後メッセージを削除します。これには、ワーカーを常時起動、もしくはバッチを定期実行するなどの方法がありそうです。
パターン②: Transaction log tailing
データベースのトランザクションログ(コミットログと呼ばれることもある)をテーリングさせる方法です。弊社で利用している MySQL の場合、binlog を使うことができます。*4
Amazon Aurora だと AWS DMS も使えるかもしれないです。(同僚談)

また、著者は以下のように述べています。
- このアプローチはあまり知られていないが、非常にうまく機能する
- 問題は、実装するために何らかの開発作業が必要になること
🌌 サーガによるトランザクション
RDB(リレーショナルデータベース)は トランザクションによってデータの整合性を担保しています。
しかし、マイクロサービスでは、各サービス内でしかデータベースのトランザクションを使えないため、他の方法で整合性を担保する必要があります。
『Azure アーキテクチャセンター』 では、サーガ(Saga)と呼ばれるパターンが紹介されています。主にマイクロサービスで使われている概念ではありますが、モノリスでも非同期処理を行っている場合は参考になる概念でしょう。
🔙 保証トランザクションによるロールバック
マイクロサービスにおいて、一連の処理が途中で失敗した場合、それまでの処理を逆に辿って元に戻す保証トランザクションを実行することで、データ整合性を担保します。
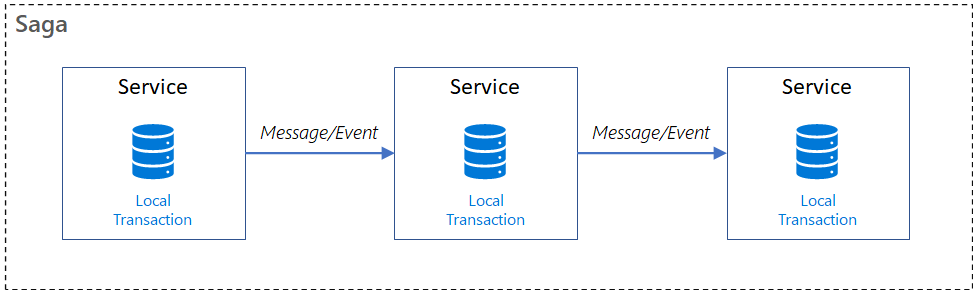
保証トランザクションの実装方法としては、コレオグラフィとオーケストレーションがあります。
🕺 コレオグラフィ
各サービスがイベントをパブリッシュし、また、必要なイベントをサブスクライブすることで協調して動きます。
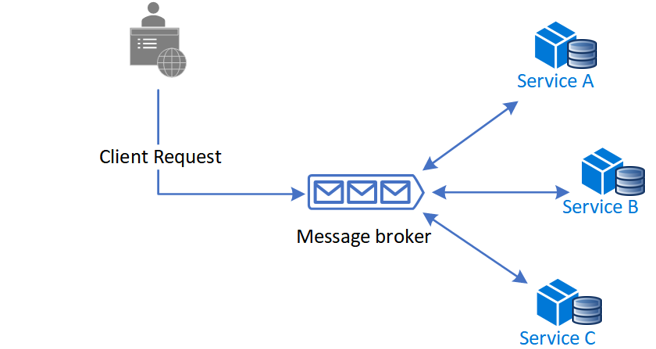
関連するサービスやイベントの数が少ないうちは、実装コストが低く済みます。
ただし、数が増えてくるとパブリッシュやサブスクライブを行う実装が分散し、処理の全体像を把握するのが難しくなるでしょう。
🎻 オーケストレーション
各サービスは、オーケストレーターとやりとりをします。オーケストレーターは、各サービスから受け取ったメッセージを元に、どのサービスにメッセージを送るか判断します。

Azure アーキテクチャセンター『saga 分散トランザクション パターン』より
コレオグラフィに比べて、全体の処理が把握しやすくなるでしょう。
ただし、オーケストレーターにロジックが集中するというデメリットがあります。
🆚 コレオグラフィ VS オーケストレーション
サービスやイベントの数が少ないうちは、コレオグラフィでも十分かもしれません。
ただし、数が増えてきて全体像の把握し辛くなったり、保証トランザクションの実行やエラーが起きた際のリカバリが難しくなってきた場合、オーケストレーションを検討すると良いでしょう。
クラウドインフラのマネージドサービスを活用すると、比較的容易にオーケストレーションを導入することができます。
- AWS
- AWS Step Functions
- GCP
- Workflows
- Azure
- Azure Logic Apps
ちなみに、Ruby にも gush という gemがあって、Redis か ActiveJob を使ってワークフローを組むことができます。
ここでは例として、私が使用経験のある AWS Step Functions をご紹介したいと思います。
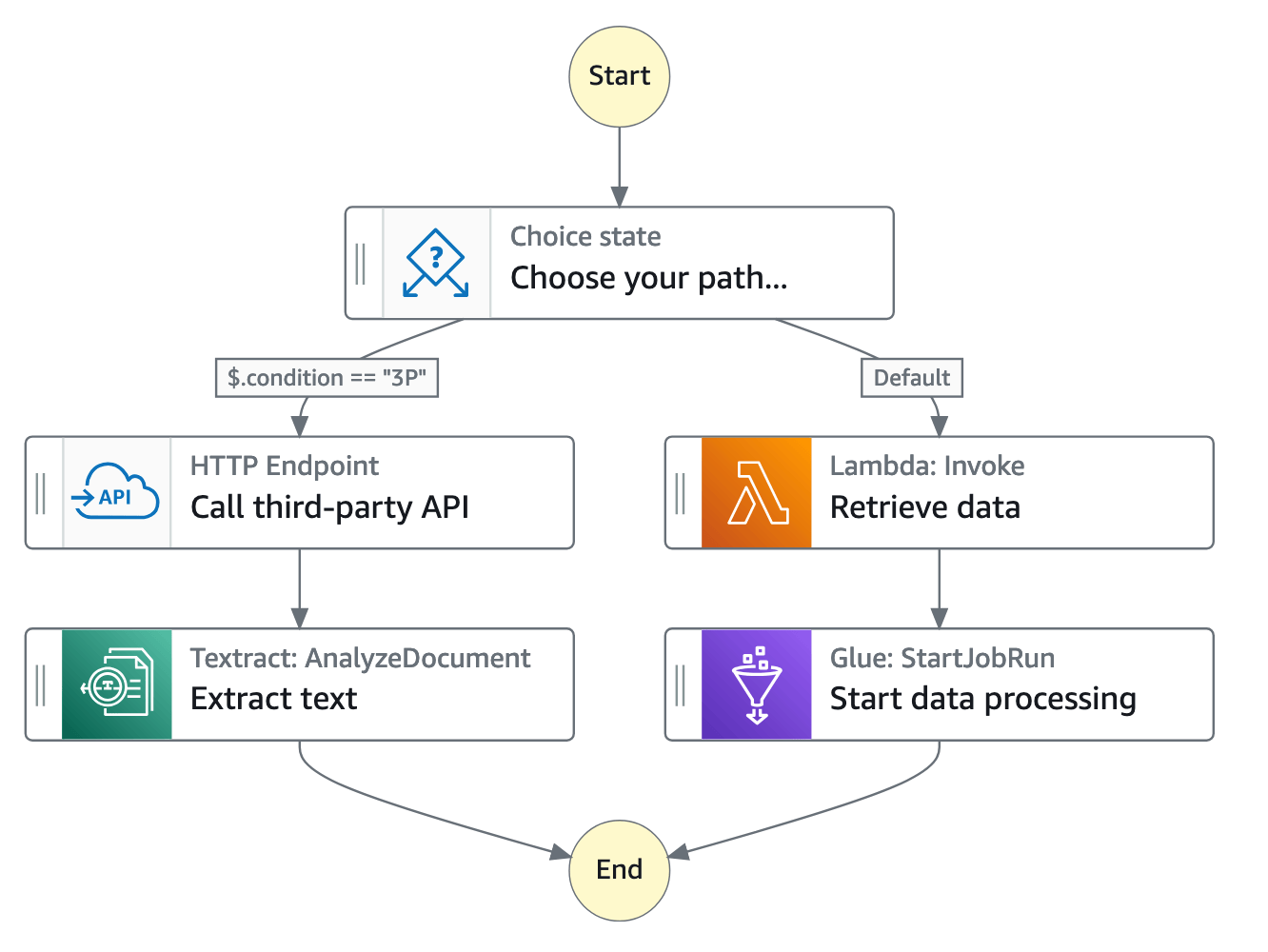
Step Functions は、状態に応じて処理を条件分岐させることができます。上記画像の例だと、 Choice state で condition == "3P" の場合にサードパーティAPIを呼び出して、それ以外は Lambda を実行しています。このように、ワークフロー定義を元に分かりやすくビジュアライズされるところも特徴です。
また、ワークフローをJSON で定義することができます。
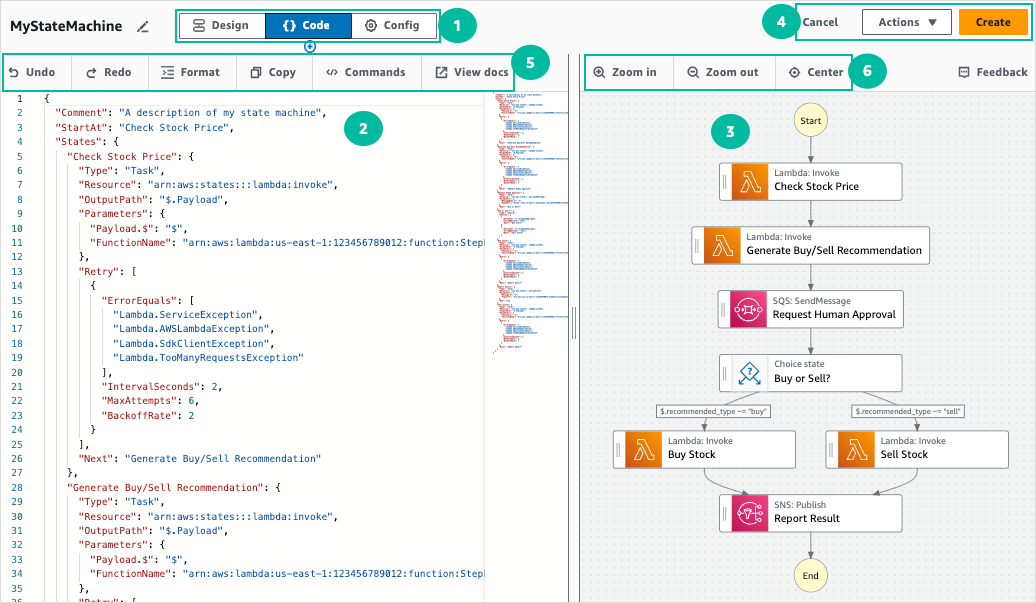
実行結果も分かりやすく表示してくれます。
さらに、Step Functions はワークフロー定義とは別に状態データとして JSON を持っています。私のイメージを 💳 例) B/43 アプリのカード発行フロー で説明すると以下のような感じです。
まず、以下のようなインプットでワークフローを開始します。
{ "インプット": { "ユーザーID": "xxx", "カード名義": "SMARTBANK MOKUO" } }
ワークフローの各タスクのアウトプットを、状態 JSON に含めることができます。
例えばカード発行後には、以下のような状態をつくることができます。
{ "インプット": { "ユーザーID": "xxx", "カード名義": "SMARTBANK MOKUO" }, "カード発行申請アウトプット": { ... }, "カード発行アウトプット": { ... } }
もちろん、前のタスクのアウトプットを後ろのタスクで上書きしたりすることも可能です。
また、状態 JSON のデータを元に、Step Functions 側で次に実行する処理を分岐させたり、ワークフロー自体を完了させたりすることができます。
🤝 スキーマを定義して、より安全に非同期処理を行う
非同期処理をメッセージキューで行う場合、JSON 形式を使うことが多いでしょう。
その場合、 JSON Schema を定義して、メッセージ送信側と受信側でバリデーションを行うことで、より安全に非同期処理を行うことができます。
Ruby には例えば json-schema というgem ライブラリがありますし、他のプログラミング言語でも同様の機能を持つライブラリはあるはずです。
こちらからも JSON Schema のバリデーションを行うライブラリを探すことができます。
また、例えば Amazon SQS はバイナリデータも扱うことができるため、 Avro や Protobuf などのバイナリフォーマットでバリデーションを行うこともできるでしょう。
おわりに
いかがでしたでしょうか。
アーキテクチャや設計を見直すことで、開発コストや運用コストを大幅に改善することも可能だと考えています。これは当然、事業スピードの成長に繋がるでしょう。
ボリュームのある内容になってしまいましたが、部分的に取り入れるだけでも効果が期待できるような構成になるよう意識しました。
ぜひ、試してみてください!
ご意見・ご感想も募集しております!!
参考情報
- O'Reilly Japan - SQLアンチパターン
- WEB+DB PRESS Vol.130|技術評論社
- O'Reilly Japan - ソフトウェアアーキテクチャの基礎
- マイクロサービスパターン[実践的システムデザインのためのコード解説] (impress top gear) | Chris Richardson, 樽澤広亨, 長尾高弘 |本 | 通販 | Amazon
- Azure アーキテクチャ センター - Azure Architecture Center | Microsoft Learn
- Step Functions とは - AWS Step Functions
P.S.
2024年11月12日に株式会社スマートバンクはシリーズBの資金調達を行ったことを発表しました!
「B/43」は、お金を使う・可視化・貯める・増やすの全サイクルに対してAI・LLMを活用したプロダクト開発をさらに加速していきます。B/43が大きく成長していくタイミングで一緒に働く仲間を募集しています。ぜひ興味のある方はこちらの特設サイトをご覧ください。
株式会社スマートバンクでは、エンジニアを絶賛大募集中です!!
明日の 株式会社スマートバンク Advent Calendar 2024 はPMの jou さんです。お楽しみに!
*1:便宜上、実際のカード発行フローを簡略化したものになっていますので、ご注意ください
*2:パターン①~③を最初に学んだのは、英語で書かれた Web の記事でしたが、引用元として該当する URL を発見することができませんでした。
*3:DBトランザクションとメッセージ送信のパターンは以下の3パターンが考えられますが、いずれも整合性を担保できない可能性があります
- DB トランザクションのコミット後にメッセージ送信する
- メッセージ送信だけ失敗する可能性がある
- DB トランザクション内でメッセージ送信する
- メッセージ送信に失敗した場合は DB トランザクションがロールバックされるが、メッセージ送信に成功した後に、DBトランザクションのコミットに失敗する可能性がある
- メッセージ送信後に DB トランザクションを開始する
- DBトランザクションだけ失敗する可能性がある
*4:書籍では、このアプローチが実際に使われている事例がいくつか紹介されていて、その1つに著者が作った Eventuate Tramというオープンソースのライブラリもありました。
データベーストランザクションの一部としてメッセージをパブリッシュする機能と、重複メッセージの検出機能が実装されているようです。
- DBトランザクションだけ失敗する可能性がある