はじめに
サーバーサイドエンジニアの kurisu(ryomak) です。 普段は、カード決済やあとばらいチャージに関連する機能の開発・運用を行っております。
本記事でお話しすること
本記事では、インデックス追加によって決済レスポンスタイムを改善した事例をご紹介します。具体的なインデックス設計の検討や実行計画の見直しを通じて、どのようにレスポンスタイムを最適化したのか、その裏側を詳しく解説します。インデックス追加によるパフォーマンスチューニングの際の参考になれば幸いです。
決済処理の遅延の検知
事の発端
株式会社スマートバンクでは、サーバーサイド全員で、2週間に1回のパフォーマンスミーティング(パフォミ) を実施しており、全てのサーバーのメトリクスを確認しています。
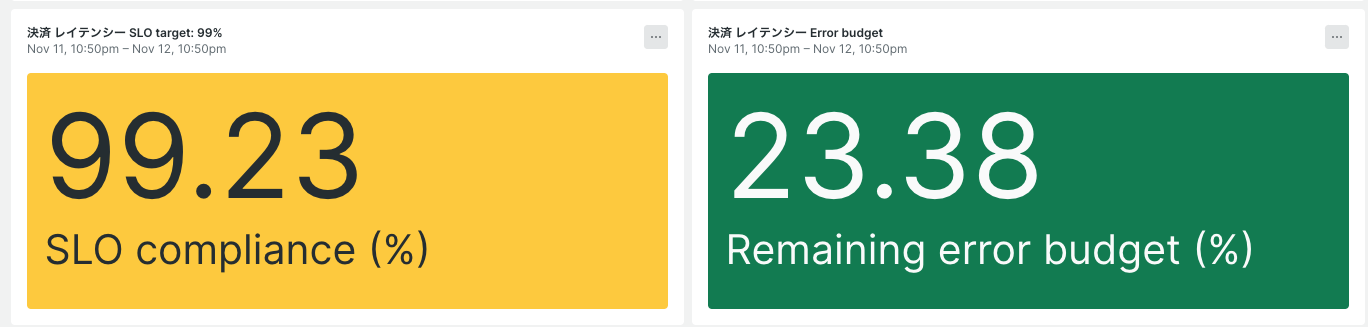
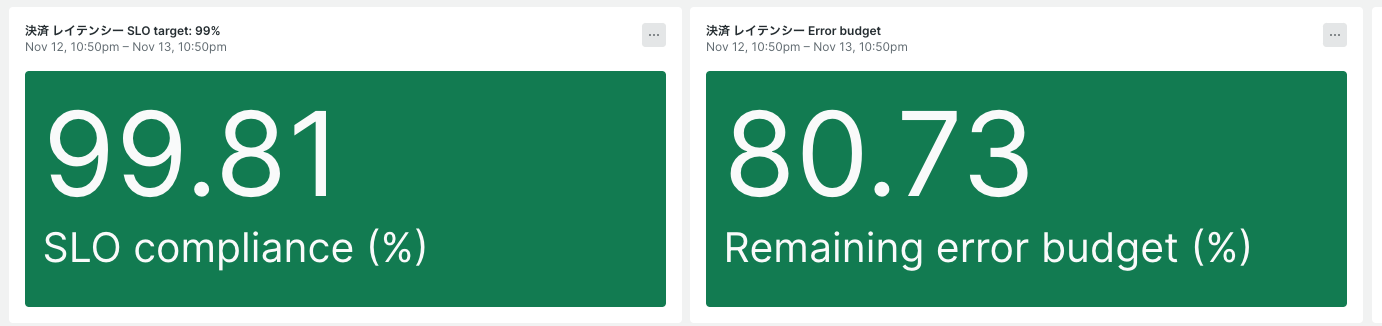
SREチーム主導でSLI/SLOを定められており、決済には、健全なレスポンスタイムが定義されています。そのレスポンスタイムを超えると以下画像のエラーバジェットが減っていくという形になっています。*1パフォミの中で、決済のエラーバジェットの減少が発覚し解消するために調査を開始することになりました。
実行環境
Aurora MySQL 3.04.3 (MySQL 8.0.28 互換)
原因調査
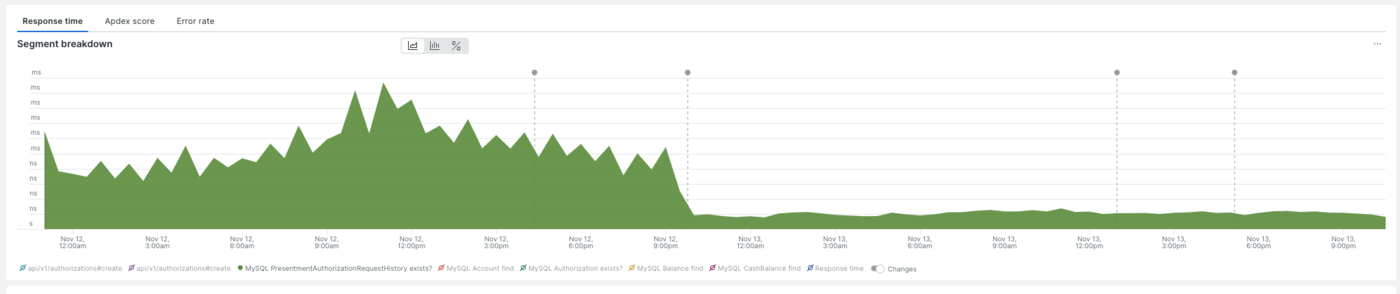
NewRelicを用いて、対象APIの原因調査を進めました。まとめると以下です。
- 全体が悪化しているようには見えない
- しかし、99パーセンタイルは日毎に増えていっている
- 1つのクエリ時間が線形的に伸びていっている。これによって一部の決済がエラーバジェットを食い潰している
遅くなったクエリの特定
前提:決済データ構造
クエリの前に、決済のデータ構造を簡略化したものを説明します。
ER図はこちらになります。 オーソリゼーションに履歴が1対多で紐づいている形です。
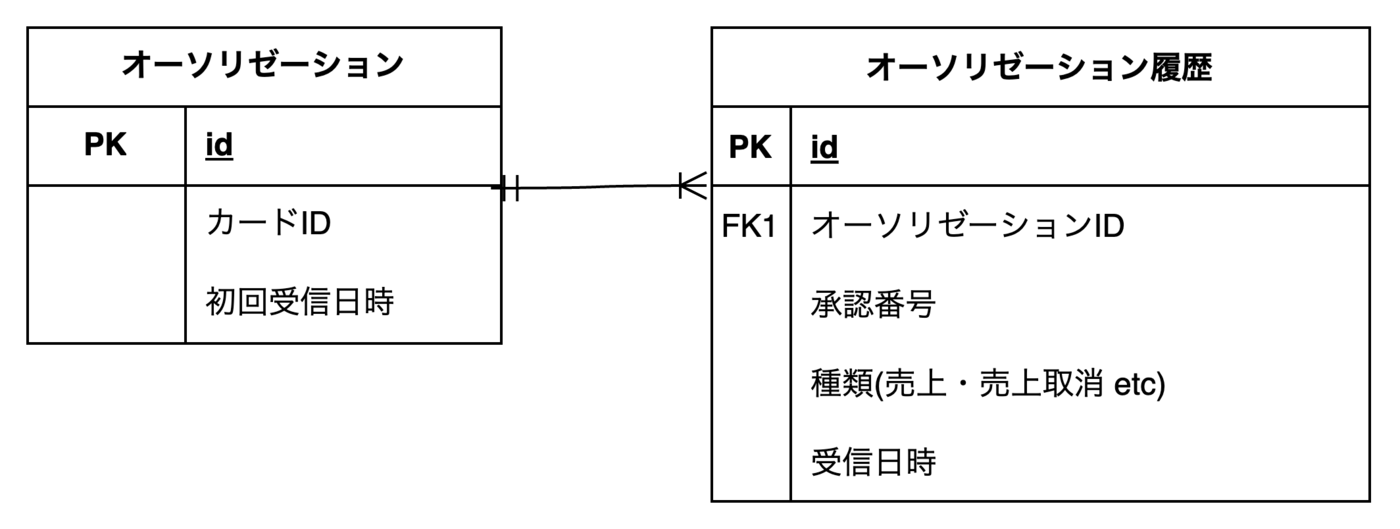
1つの決済につき1つのオーソリゼーションがあり、1つの決済には取り消しなども存在するため履歴として紐づいて保存されています。
オーソリゼーションについて詳しく知りたい方は、こちらの記事 をご参照ください。また、既に オーソリゼーション.カードID にインデックスが貼られているものとします。
承認番号(承認番号)
承認番号は決済を承認した時に、イシュアー(カード発行会社)が発行する番号のことです。レシートに記載されています。B/43の仕様として、現在有効なオーソリゼーションの中では一意な承認番号が割り当てられるようにする必要があります。

特定したクエリ
実行時間が伸びているクエリは以下でした。 承認番号を採番する際に、同じ承認番号がまだ存在していないことをチェックするクエリです。(本来はステータスや種類などさまざまなWHERE条件がありますが、今回は必要な箇所だけに絞っています) 仕様としては、カードID毎に有効なオーソリゼーションで承認番号を一意にする必要があります。
SELECT 1 AS one FROM オーソリゼーション履歴 AS h INNER JOIN オーソリゼーション AS a ON a.id = h.オーソリゼーションID WHERE a.カードID = ? AND h.承認番号 = ? AND h.受信日時 BETWEEN ? AND ?
実行計画
MySQLの内部処理のイメージ
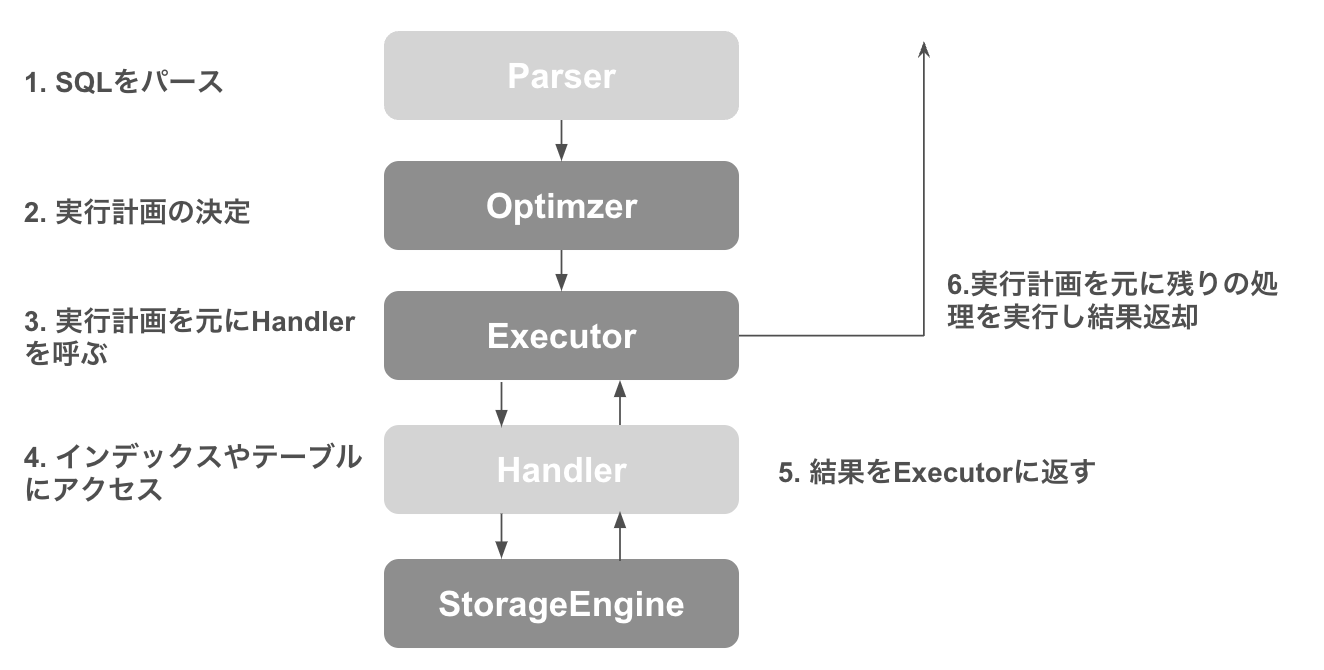
簡易的に表すと上記のような役割があります。
特長
- Executor
- Handlerから返却された結果を元に、実行計画の残りを実行
- Storage Engine でフィルタリングされなかったレコードをフィルタリングする
- 他にもJoinやUsing filesortなども、Executorで実行される
- 処理が遅い
- Executorの仕事量は、Storage Engineからのレコード数に大きく影響される
- Handlerから返却された結果を元に、実行計画の残りを実行
- Optimizer
- Storage Engineから返却される統計情報を使ってクエリの書き換えを含めた実行計画を決定する
- Storage Engine
- インデックスを活用することで、取得するレコード数を減らすことができる
実行計画とは
統計情報をもとに、「どのようにクエリを書き換え、どの順番でどのようなインデックスを使って処理をするのが最適化を見積もること」です。
InnoDBの統計情報は、テーブル全体から一部の情報をランダムに選んで全体を推測する形でのサンプリング統計になっています。
クエリの最適化を図る際は、この実行計画を見て改善していきます。
実行するクエリの前に、EXPLAINをつけると確認できます。
本記事で出てくる項目を一部紹介します。 詳細はこちらを参考にしてください
| 項目 | 説明 |
|---|---|
| table | 対象のテーブル名 |
| key | 実際に選択されたインデックス |
| key_len | 選択されたインデックスのキーの長さ。長ければ長いほど、インデックスをフェッチする |
| rows | テーブルからフェッチされてくるレコードの見積もり |
| filtered | フェッチしたレコードを WHERE でどのくらい絞り込めるかの見積もり。rows×filtered には次のテーブルと結合された行数が表示される |
| Extra | Optimizerがどのような実行計画を選択したか。 例えば Using index の場合、インデックスだけで結果を出せており、Executorのフィルターは行われない。 |
Optimizerは、クエリの実行で発生する様々な操作コストの見積もりが一番低くなるような実行計画を選択します。*2 コストが大きいものの一つとしてあげられるのは、Executorでのフィルター処理です(図の6の処理)。行データをスキャンしチェックする必要があるためです。
ネステッドループ結合(NLJ) *3
JOINするときのメインのアルゴリズムです。ループ内の最初のテーブルから行を一度に 1 つずつ読み取り、各行を、結合の次のテーブルを処理するネストしたループに渡します。
外側の表を駆動表、内側を内部表と言います。
foreachのようなイメージです。
例
## 条件にあったレコードをフェッチする for each row in (駆動表にてWhereで絞られたレコード) { ## 条件にあったレコードをフェッチする for each row in (内部表にて結合条件とWhereで絞られたレコード) { ## 結果をクライアントに返す send_to_client(user,team) } }
NLJもコスト計算に含まれているため、JOINの順番もOptimzerによって選択されます。
JOINの場合は、 駆動表のコスト +(駆動表のフィルタ済み行数)*内部表のコスト が最小になる実行計画を選びます。
JOINにおける最適化の方針としては、
- インデックスを用いて、駆動表もしくは内部表のレコード数を減らす
- 駆動表の行数が少ない方が効率的になる *4
- インデックスを用いて、フェッチの速度を上げる
特定したクエリの実行計画を見てみます
| object_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | |-------------|-------------------- |------------|------|---------------|-----|---------|--------------------|---------|----------|-------------| | SIMPLE | オーソリゼーション | NULL | ref | ... | ... | 8 | const | 27050 | 100 | Using index | | SIMPLE | オーソリゼーション履歴 | NULL | ref | ... | ... | 4 | オーソリゼーション.id | 4.81 | 1 | Using where |
駆動表はオーソリゼーションになっており、既存のカードIDに対する、インデックスが採択され、Using indexが使われています。filtered:100%になっておりExecutorに仕事をさせず効率的に見えます。しかし、NLJ*5の動きを考えると、内部表では、27050回 Using where でのフェッチが行われると見積もられているため、効率が悪いと言えます。
遅くなってしまう原因
オーソリゼーション(決済レコード)が多いユーザほど、Executor でフィルタするレコード数が増加し、クエリ全体が遅くなることが今回の問題の原因と考えられます。99パーセンタイルの遅延が顕著に悪化している点にも納得がいきます。
対応検討
方針
原因が判明したところで、対応方針の検討をしました。テーブル構造やアプリケーションロジックの変更など複数のアイデアが出ましたが、通常の機能開発もあり、時間をかけることができなかったため、インデックスでの対応で進めることにしました。では、今回のケースに関してどのようにインデックスを追加すると一番効果的なのかを検証していきます。
検証項目
インデックスを試すにあたって、検証項目は以下です
対象クエリの実行計画
EXPLAIN /EXPLAIN ANALYZEを使って効率的に処理されているかを比較します。対象のインデックスが正しく採用されていることをチェックした上で、比較するようにします。
EXPLAIN ANALYZE は、実際にクエリを実行し、イテレータごとに実行時間を計測するものです。今回は、JOINが存在しているのでNLJがどのように実行されているかを把握する材料にできます。
対象クエリの実行時間
対象クエリを何回か実行してから、再度、5回同じクエリを実行し、実行時間の平均をとりました。同じクエリを何回か実行するとバッファプールに行データがキャッシュされるため、高速に返却されるようになります。比較の前提条件を一致させるため、最初に何回かクエリを実行してバッファプールに対象レコードがキャッシュされている状態で計測するようにします。
今回は、インデックス前の実行時間からどれだけ削減されるかを見ていきます
インデックスの「アタリ」をつける
実際に対象クエリで時間がかかるユーザを対象に検証しました。無作為にインデックスを貼ることはせず、効果があるだろうと推測できるものに対して追加するようにしました。
- 日時での範囲検索にインデックスを追加する
- アプリケーションとして有効な決済だけに絞る必要があるため、有効な期間での範囲検索が必須だと考えました。データ量を抑えるためにも、日付へのインデックス追加するようにします。
- 複合インデックスでは、指定するカラムの順番がかなり重要です。範囲検索は最後に持ってくるようにします。B+木の性質上、範囲検索を前に持ってきてしまうと、後ろのインデックスはほとんど効かず走査されてしまうためです。*6
- インデックスサイズをなるべく増やさないようにする
- セカンダリインデックスの使われ方の中で一番効率的なのは、実行されるクエリに対してカバリングインデックスとなるケースです。
- クラスタインデックスを走査し行データを取得する必要がないため高速になります。
- しかし、データを挿入したり更新したりする際には、インデックスも同時に更新されます。そのため、インデックスに含まれるカラムが増えたり、インデックス自体が大きくなると、それに伴い処理の負担(オーバーヘッド)も増加してしまいます。
- そのため、アプリケーションに対してなるべく頻繁に利用されるカラムだけにインデックスだけを選択するもしくは、インデックスサイズを小さくしておく必要があります。
- なるべく少ないインデックスサイズで、効果的にレコードが絞れる複合インデックスを検討しました。
- セカンダリインデックスの使われ方の中で一番効率的なのは、実行されるクエリに対してカバリングインデックスとなるケースです。
① オーソリゼーション履歴:(オーソリゼーションID, 承認番号,受信日時)
CREATE INDEX idx_xxx ON オーソリゼーション履歴 (オーソリゼーションID, 承認番号, 受信日時);
試した理由
既存だと、オーソリゼーション履歴が Using where になっていて、Executorでのフィルタリングになっており非効率でした。
そのためインデックスで、オーソリゼーションのフェッチを改善すれば、速くなるだろうと考えました。
結果
-- EXPLAIN | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | |-------------|--------------------|------------|-------- |---------------|-----|---------|----------------------|---------|----------|------------------------------------| | SIMPLE | オーソリゼーション | NULL | ref | ... | ... | 17 | NULL | 27758 | 100 | Using index. | | SIMPLE | オーソリゼーション履歴 | NULL | ref | ... | ... | 8 | オーソリゼーション.id | 1 | 5 | Using index condition;Using where. |
-- EXPLAIN ANALYZE -> Limit: 1 row(s) (cost=30580.16 rows=1) (actual time=68.067..68.067 rows=0 loops=1) -> Nested loop inner join (cost=30580.16 rows=1388) (actual time=68.066..68.066 rows=0 loops=1) -> Covering index lookup on オーソリゼーション using index_オーソリゼーション_on_カードID (カードID=1xxxxx) (cost=2830.90 rows=27758) (actual time=0.037..15.401 rows=14846 loops=1) -> Filter: ((省略) and (省略) and (オーソリゼーション履歴.種類 not in (省略))) (cost=0.90 rows=0) (actual time=0.003..0.003 rows=0 loops=14846) -> Index lookup on オーソリゼーション履歴 using idx_auth_req_histories_optimized (オーソリゼーションID=オーソリゼーション.id, 承認番号='613531'), with index condition: (オーソリゼーション履歴.受信日時 between 'xxxx' and 'yyyy') (cost=0.90 rows=1) (actual time=0.003..0.003 rows=0 loops=14846)
実行時間
31%削減
解釈
Using index conditionになってオーソリゼーション履歴が効率的にフェッチされるようになっていますが、 オーソリゼーションの行が多いままなので、オーソリゼーション履歴のフェッチ回数は変わらず、実行時間はそこまで削減されませんでした。
Using index condition とは
- Using index conditionは、インデックスコンディションプッシュダウン(ICP)と呼ばれる最適化が行われています。
- ICPは、インデックスのみで解決できないテーブルフェッチが必要なSQLかつ、Whereにインデックスに使用されているカラムの範囲検索条件がある時に適用されます
- Storage Engine内で、インデックスによって取得する行を削減します。
② オーソリゼーション:(カードID, 初回受信日時)
CREATE INDEX idx_yyy ON オーソリゼーション (カードID, 初回受信日時);
試した理由 ①で出た課題としては、オーソリゼーションでフェッチされるレコードが多いことでした。カードIDだけでのフィルターだと決済が増える度に、フェッチされるレコードが増えてしまいます。そのため、日付もインデックスに加えて、有効なオーソリゼーションだけになるように絞ってみます。
クエリの修正
オーソリゼーション履歴.受信日時 での範囲検索を オーソリゼーション.初回受信日時 にする
結果
-- EXPLAIN | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | |-------------|--------------------|------------|-------- |---------------|-----|---------|--------------------|---------|----------|------------------------------------| | SIMPLE | オーソリゼーション | NULL | range | ... | ... | 17 | NULL | 3638 | 100 | Using where;Using index. | | SIMPLE | オーソリゼーション履歴 | NULL | ref | ... | ... | 8 | オーソリゼーション.id | 1 | 4.81 | Using where |
-- EXPLAIN ANALYZE -> Limit: 1 row(s) (cost=4896.36 rows=1) (actual time=2861.004..2861.004 rows=0 loops=1) -> Nested loop inner join (cost=4896.36 rows=182) (actual time=2861.003..2861.003 rows=0 loops=1) -> Filter: ((オーソリゼーション.カードID = 1xxxxx ) and (オーソリゼーション.初回受信日時 between 'xxxx' and 'zzzz')) (cost=739.70 rows=3638) (actual time=0.025..15.464 rows=3638 loops=1) -> Covering index range scan on オーソリゼーション using idx_オーソリゼーション_カードID_初回受信日時 over (カードID = 1xxxxx AND 'xxxx' <= 初回受信日時 <= 'yyyy') (cost=739.70 rows=3638) (actual time=0.022..7.320 rows=3638 loops=1) -> Filter: ((省略) and (省略) and (オーソリゼーション履歴.種類 not in (省略)) and (オーソリゼーション履歴.承認番号 = '613531')) (cost=1.04 rows=0) (actual time=0.782..0.782 rows=0 loops=3638) -> Index lookup on オーソリゼーション履歴 using index_オーソリゼーション履歴_on_オーソリゼーションID (オーソリゼーションID=オーソリゼーション.id) (cost=1.04 rows=1) (actual time=0.778..0.780 rows=1 loops=3638)
実行時間
45%削減
解釈
- オーソリゼーションでフェッチされる行数が3638に減りました。
- filteredも100%でカバリングインデックスになっており、かなり効率的に見えます
- しかしそもそも存在しないことをチェックするクエリなので、対象レコードがほとんど存在しないことを考えると、ループで3638回オーソリゼーション履歴をフェッチされているのは、無駄が多そうです。
③ オーソリゼーション履歴:(承認番号,受信日時)
CREATE INDEX idx_zzz ON オーソリゼーション履歴 (承認番号, 受信日時);
試した理由
- オーソリゼーションだけではExecutorに渡すレコードを絞りきれないので、オーソリゼーション履歴側で絞ることを検討します。
承認番号はなるべく一意になるようセットされる値なので、テーブル全体を通しても被ることが少ないはずです。(カーディナリティが高いので効果的だと言えそうです)承認番号のみだと、同じ承認番号が全てフェッチされてしまうため、決済が増えるたびにフェッチされる行数が増えていきます。受信日時もインデックスに追加し有効なオーソリゼーションだけに絞る範囲検索でフェッチするレコードを減らす事が有効であると考えました。
結果
-- EXPLAIN | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | |-------------|--------------------|------------|-------- |---------------|-----|---------|--------|---------|----------|------------------------------------| | SIMPLE | オーソリゼーション履歴 | NULL | range | ... | ... | 1032 | null | 3 | 1.67 | Using index condition; Using where | | SIMPLE | オーソリゼーション | NULL | eq_ref | ... | ... | 8 | const | 1 | 5 | Using where |
-- EXPLAIN ANALYZE -> Limit: 1 row(s) (cost=4.17 rows=0) (actual time=0.067..0.067 rows=0 loops=1) -> Nested loop inner join (cost=4.17 rows=0) (actual time=0.066..0.066 rows=0 loops=1) -> Filter: ((省略) and (省略) and (オーソリゼーション履歴.種類 not in (省略))) (cost=4.12 rows=0) (actual time=0.065..0.065 rows=0 loops=1) -> Index range scan on オーソリゼーション履歴 using idx_auth_req_histories_optimized over (承認番号 = '613531' AND 'xxxx' <= 受信日時 <= 'yyyy'), with index condition: ((オーソリゼーション履歴.受信日時 between 'xxxx' and 'yyyy') and (オーソリゼーション履歴.承認番号 = '613531')) (cost=4.12 rows=3) (actual time=0.042..0.063 rows=3 loops=1) -> Filter: (オーソリゼーション.カードID = 1xxxxx ) (cost=1.10 rows=0) (never executed) -> Single-row index lookup on オーソリゼーション using PRIMARY (id=オーソリゼーション履歴.オーソリゼーションID) (cost=1.10 rows=1) (never executed)
実行時間
65%削減
解釈
- 駆動表が逆転してます。Optimizerはオーソリゼーション履歴を先に見た方が効率的と判断したようです。
- 特に重要なのはオーソリゼーション履歴のrowsが3件になっていることです。Executorでの処理行数が大幅に減らせているので、全体のコストがかなり減っていることがわかります
結論
③ オーソリゼーション履歴:(承認番号,受信日時)のインデックスを追加することにしました。実行計画に関して、オーソリゼーションだと、フェッチする行が絞りきれなかったですが、先に オーソリゼーション履歴 からチェックすることで、駆動表の rowsが減り対象行が絞り込めました。実行時間に関しても、ウォームアップ後でも65%削減され、バッファプールにデータがない状態だと、95%削減されたのでインデックスの効果は高そうです。
比較表
| インデックス内容 | 実行時間 | 解釈 |
|---|---|---|
| ① オーソリゼーション履歴:(オーソリゼーションID, 承認番号, 受信日時) | 31%削減 | オーソリゼーションが効率的にフェッチされるようになったが、オーソリゼーションの行は多いまま |
| ② オーソリゼーション:(カードID, 初回受信日時) | 45%削減 | ①に比べるとオーソリゼーションは絞れたが、数千行のレコード取得見積もりになっている |
| ③ オーソリゼーション履歴:(承認番号, 受信日時) | 65%削減 | オーソリゼーション履歴が駆動表になり、レコード見積もりが3件となり一番効果が高かった |
結果
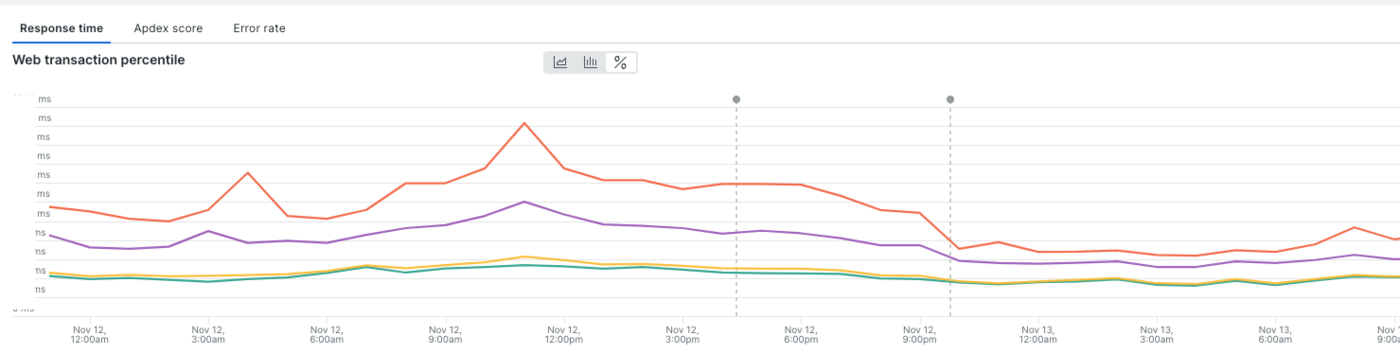
本番環境に反映したところ、以下のような結果になりました。
対象クエリ
無事綺麗な崖ができました。
API全体
99%タイルだけでなく、Averageも改善されました。
| 決済レイテンシー | |
|---|---|
| Average | 17.3%改善 |
| 99パーセンタイル | 35.1%改善 |
99パーセンタイルもガクッと下がりエラーバジェットが復活しました!
所感
今回のパフォーマンスチューニングでの学び・所感です。
- アプリケーションの仕様とセットでインデックスを考える
- Executorが処理する行数を減らすことが重要。
- JOINの際は、フェッチの動きをイメージして、駆動表を減らす事を考える
- そのためにも、アプリケーションの挙動も踏まえカーディナリティの高いものを選ぶ
- 範囲検索で利用するカラムは、複合インデックス時において、後ろに持っていく
- カバリングインデックスではなくても、処理する行数が許容範囲内になるインデックスを探す
- Executorが処理する行数を減らすことが重要。
- 実行計画と合わせて、実際の実行時間も出しておくと、効果の比較がしやすい
- バッファプールへのデータ保持の有無によって速度に大きな差が出るので比較する時は条件を一致させる。
終わりに
本記事では、インデックスを追加し、決済レスポンスタイムを改善した事例についてご紹介しました。
インデックス追加によるパフォーマンスチューニングの際の参考になれば幸いです。
株式会社スマートバンクではサーバーサイドエンジニアを募集しております!連絡お待ちしております!!
参考情報
- MySQL データベースの負荷対策/パフォーマンスチューニング備忘録 インデックスの基礎〜実践 #Database - Qiita
- MySQLテーブル設計入門 | PDF
- 雑なMySQLパフォーマンスチューニング | PDF
- MySQLのインデックスの貼っていいとき悪いときを原理から理解したいよ😭
- 実例で学ぶ、JOIN (NLJ) が遅くなる理屈と対処法 #MySQL - Qiita
*1:株式会社スマートバンクのエラーバジェットについては「我々はこうしてSLI/SLOを設計して運用を始めました -これからSLI/SLOの運用を始める人に向けて-」というタイトルで登壇してきました - inSmartBankをご参照ください。
*2:MySQL :: MySQL 8.0 リファレンスマニュアル :: 8.9.5 オプティマイザコストモデル
*3:MySQL :: MySQL 8.0 リファレンスマニュアル :: 8.2.1.7 Nested Loop 結合アルゴリズム
*5:MySQL :: MySQL 8.0 リファレンスマニュアル :: 8.2.1.7 Nested Loop 結合アルゴリズム