
こんにちは。サーバーサイドエンジニア, EMをしている @godgarden です。
この記事では、株式会社スマートバンクにおける データ活用の障壁とその課題にどのように向きあって対処しているか「データ活用の現在地を紹介」したいなと思います。
同じような課題と向き合っている人の少しでも参考になれば嬉しいです!
💭 データ活用、こんな課題ありませんか?
 事業の立ち上げ当初は要求もシンプルなので、あまり気にならないんですが、事業・組織の拡大とともに複雑性を増して起こる課題ですね。
事業の立ち上げ当初は要求もシンプルなので、あまり気にならないんですが、事業・組織の拡大とともに複雑性を増して起こる課題ですね。
ボディブローみたいにジワ...ジワ…と判断のスピードと質が落ちていくんですね
背景と課題:成長とともにデータへの障壁が顕在化する


株式会社スマートバンクも例外ではなく、事業・組織が大きくなっていくにつれ、データに纏わる課題を目にする場面が増えてきました。
- データ量の増加に伴うパフォーマンス劣化
- データのサイロ化。それによって引き起こる人力データ集計
- 付け焼き刃に拡張され乱立する集計ロジック
- 似たようなクエリの大量生産
- 担当者の退職や異動によって失われる知識。主を失ったクエリ
- それでも、データは参照され続ける。
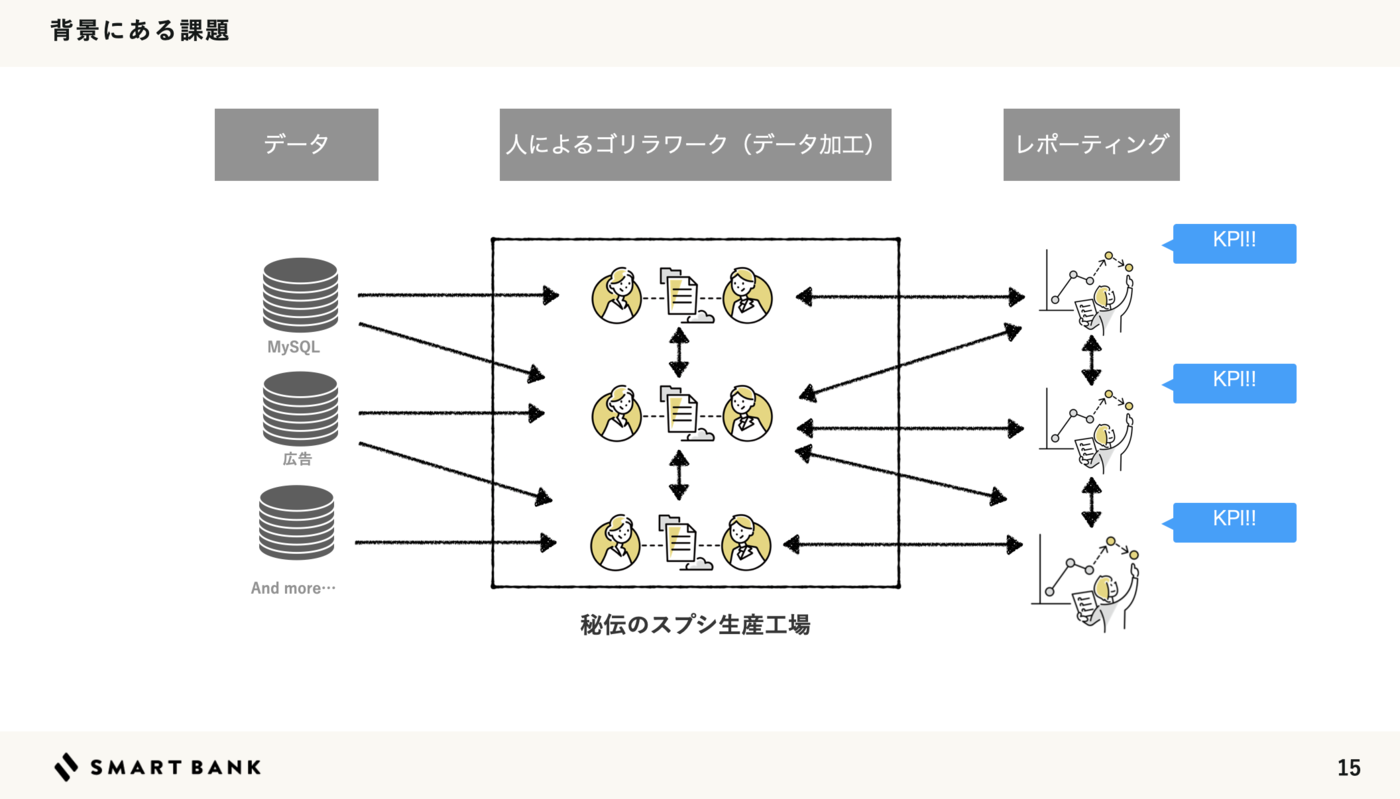
三種の神器(あまりありがたくない)
- 🧙 秘伝のクエリ・スプシ:継ぎ足しを重ねた深みのあるデータ群
- 🧟 ゾンビクエリ:Redashに潜む「生存不明だけど怖くて消せないやつ」
- 🦍 ゴリラワーク:人力パワープレイによるデータ加工・集計
上記以外にも、ワンバンクは1つのプロダクト内に多種多様なユーザー属性(家計管理・あとばらい)やニーズ・機能群(決済、課金 etc...)があり複雑です。
これらは、エンジニアであっても網羅してデータを集計するには、日に日に敷居が高くなっていました。
こうした状況の先に、何が待っているかというと…複雑に絡み合った 「データの宇宙」 の誕生ですね。


組織体制的にも事業側の開発で手一杯であったり、課題は認知しているんだけど、対処に明るいメンバーも少なかったり。 サービスが止まるわけではないので、蓋をして耐え凌ぐみたいな状態だったんですね。
技術面での対処
まず、技術面でどのように課題と向き合っているかに触れたいと思います。
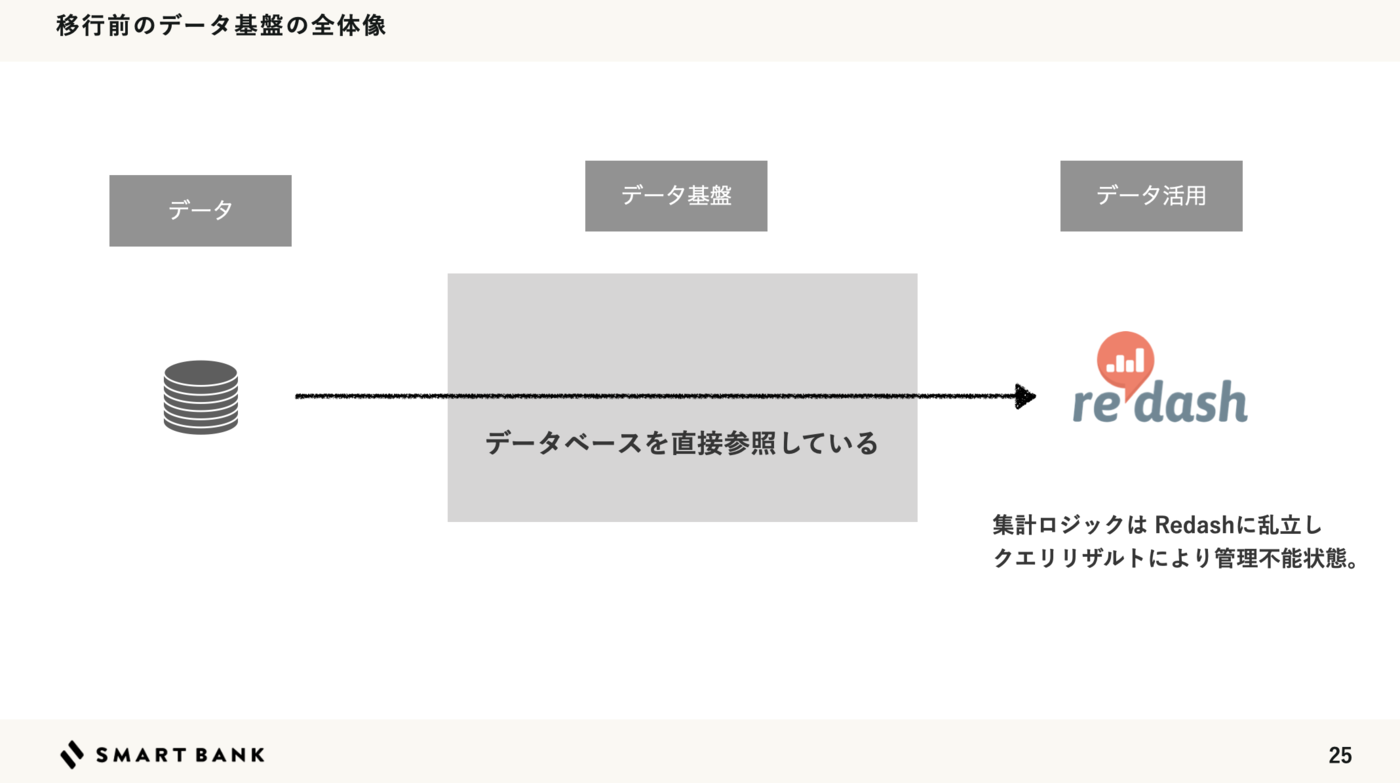
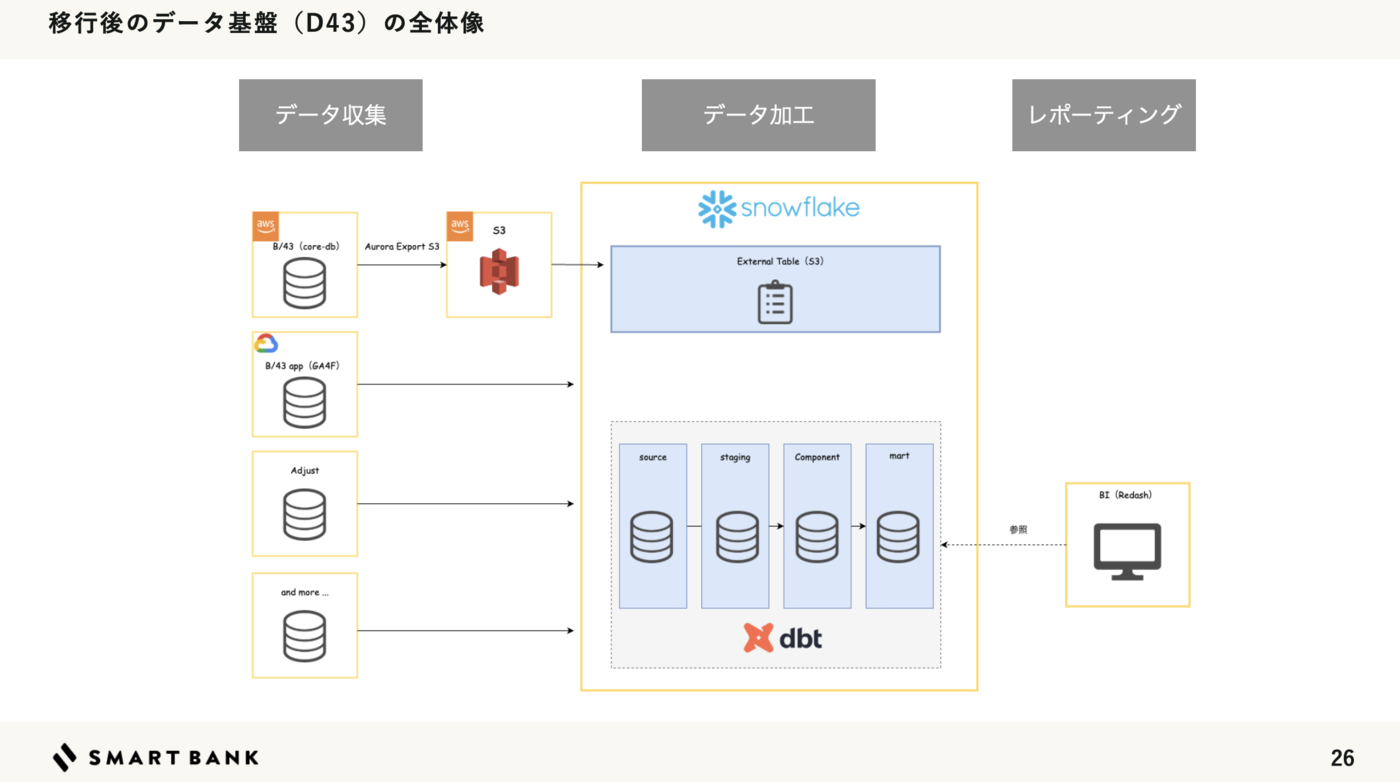
データ基盤の全体像
Snowflake × dbt でデータ基盤を構成しています。
ワンバンクは Amazon Web Services(AWS)のインフラに構築しています。 そのため分析で扱いたい主軸となるデータは AWSのデータベースにあります。
データ基盤
データ基盤として Snowflake を採用しています。 インフラは terraform-provider-snowflake で構成管理をしています。
Snowflakeを採用した理由はいくつかあるのですが、その中でも意思決定を後押したポイントは2つです。
1つ目は、プロダクトと同じクラウドサービス上で運用ができることです。
Snowflakeは構築するクラウド環境をユーザーが選択できる柔軟性があります。
それにより、データ転送のコストや煩わしさ、社内のエコシステムの恩恵やチームメンバーからの支援の受けやすさなどがありました。
2つ目は、コストコントロールの観点です。
Snowflakeはクエリの実行単位課金ではなくインスタンスの起動時間によって請求されます。 そのため、比較的コストの予測がシンプルになります。
管理者観点、利用者目線でも不慮のクエリ事故で課金爆発…(怖い!)といった不安を抱えないで良いといった、心理的な面での後押しもありました。
これら意思決定のログを株式会社スマートバンクでは、 Architectural Decision Record(ADR)としてNotionへ残す文化があります。
データに纏わる意思決定は属人化しやすいため、可能な限りADRを残すようにしてしています。
ADRについての説明はノバセルさんの記事が分かりやかったのでご参照ください。 techblog.raksul.com
データ収集
Aurora S3 Export でデータをS3にエクスポートしています。
それらを dbt-external-tables というパッケージを利用し dbt でSnowflakeの外部テーブルとして定義しています。
外部テーブルで必要となる YAML の定義は dbt macro を組み合わせたスクリプトを用意してYAML生成のコストを省エネ化するように工夫しています。
#!/bin/bash # ユーザーからの入力を受け取る read -p "Table name: " table_name read -p "Output file name (default: models/source/$table_name.yaml): " output_file output_file=${output_file:-models/source/$table_name.yaml} # JSONオブジェクトを構築 json_args=$(cat <<EOF { "source_name": "db_name", "schema_name": "dbt_staging", "table_name": "$table_name", "table_description": "$table_name", "stage_location": "@dbt_staging.d43_core/db_name.$table_name", "file_format": "dbt_staging.parquet", } EOF ) # dbt run-operationコマンドを構築 dbt_command="dbt run-operation generate_external_source_yaml --args '$json_args' --quiet" # 出力ファイルが指定されている場合、リダイレクトを追加 if [ -n "$output_file" ]; then dbt_command="$dbt_command > $output_file" echo "Executing: $dbt_command" eval "$dbt_command" echo "Output saved to $output_file" else echo "Executing: $dbt_command" eval "$dbt_command" fi # 対応するstagingテーブルの生成
{% macro generate_external_source_yaml(
source_name,
schema_name,
table_name,
table_description,
stage_location,
file_format,
loader="S3",
infer_schema=false,
auto_refresh=false
) %}
{%- set yaml_output %}
version: 2
sources:
- name: {{ source_name }}
schema: {{ schema_name }}
loader: {{ loader }}
{%- endset -%}
{{ print(yaml_output) }}
{% set result = generate_external_table_yaml(
table_name,
table_description,
stage_location,
file_format,
infer_schema,
auto_refresh,
) %}
{{ return(yaml_output) }}
{% endmacro %}
データ変換
dbt core を使ってデータの変換を行っています。
ゼロから作るからには、第2の宇宙を誕生させないようにしたいところです。
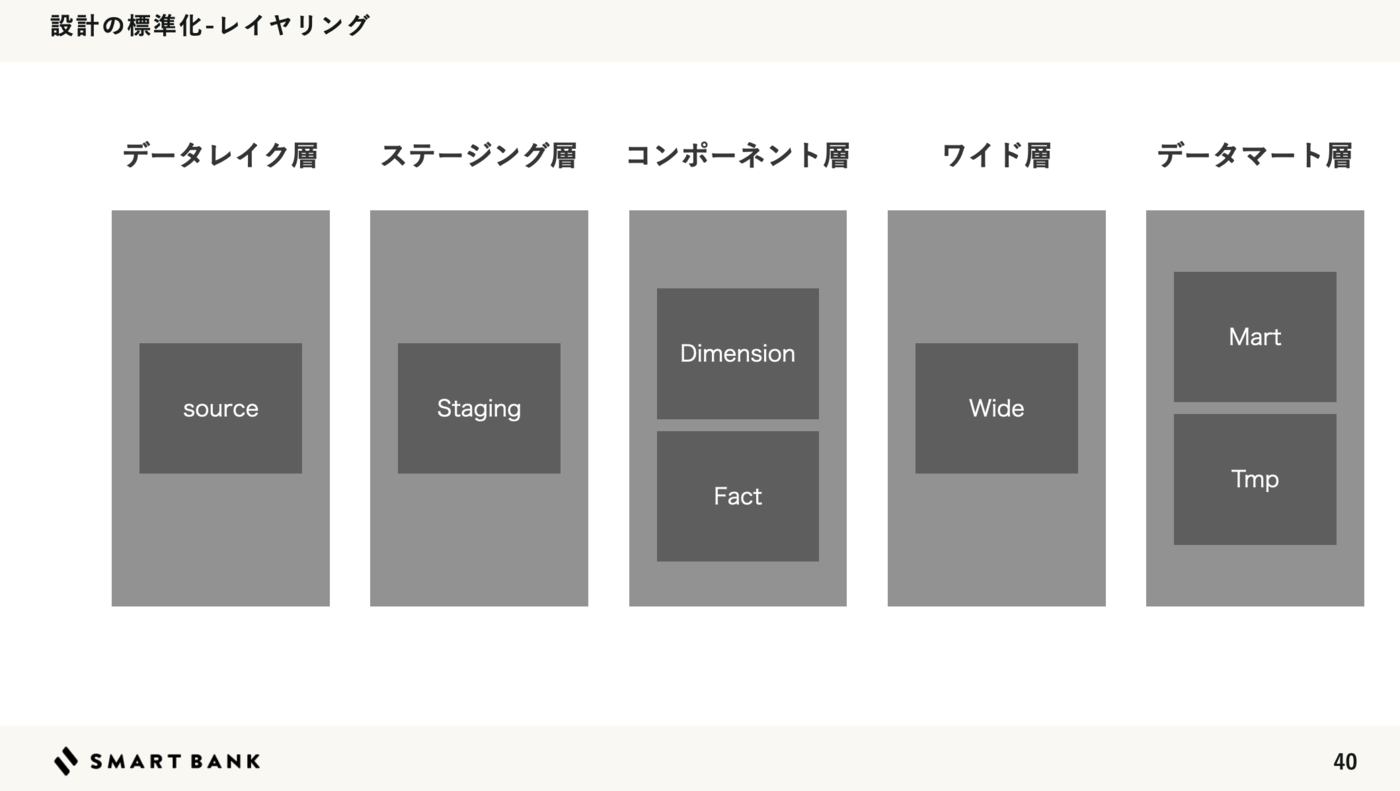
dbt best practices やチームで議論しながら以下のレイヤリング構造にしています。 モデリングに関してはディメンショナルモデリングを採用しています。
BIツール
BIツールは 長らく Redash を使っています。
しかし、OSS のメンテナンスの継続性の懸念や、Snowflakeのパスワード認証の廃止の流れもあり、Snowflakeの対となるBIは lightdash を候補に導入に向けて調査や準備を進めている最中です。
技術以外の対処
つぎに、技術以外の観点でも少しだけ触れたいと思います。
📖 ドメイン辞書で会話をする
株式会社スマートバンクでは、「チーム内でのコミュニケーションとソフトウェアの実装を円滑に結びつける」目的でドメイン辞書を運用しています。
新機能開発プロジェクトの初期で、新しい用語が生まれることが多いため、その際の手順を記載する運用となっています。


データに関わるステークホルダーは多種多様です。
異なる職種間であったり、経営と現場などレイヤーの異なるステークホルダーとコミュニケーションすることも多いです。
コミュニケーションを円滑に 繋ぐ ため ドメイン辞書を中心に会話で使う言葉、ドキュメント、データモデリングやクエリの用語を揃え、認識のズレを少なくすることを意識しています。
ルールを作り、レールを引く。
安心安全に利用できるようガイドライン(セキュアデータポリシー)も関連チームと連携し整備を進めています。

取り扱う情報の範囲、それらを適切に権限管理できるようレベルを定義し、ロールベースのアクセス制御やフローも合わせて整備しています。
これらのポリシーに沿って、データの源泉となるプロダクト開発時もカラムの暗号化、分割などテーブル設計の指針としても活用しています。
プロダクト開発とデータ活用が分断されないよう 繋ぐ 意味もあります。
仲間を増やす。
データに関わる営みは組織がスケールするためには重要とは誰しもわかるのですが、プロダクトの機能開発と違って派手さは少なく、スポットライトが当たりにかったりするんですね。縁の下のちから持ち的な感じ。
組織の人数比率的にも少数であることが多く 孤軍奮闘 に頑張ってしまいがちなんですね。
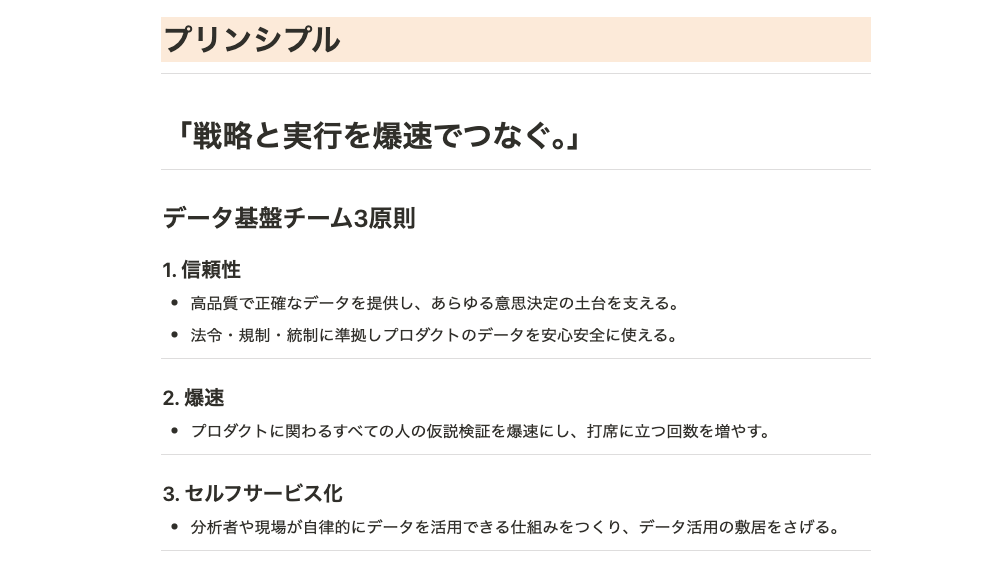
そういった背景もあり「背景にある課題」「プリンシプル」「データエンジニアリングの面白さ」など営みを社内へ伝播して仲間を増やす活動も、大切な対処の1つだと思っています。
伝播する機会をつくる・増やす。
部門定例や、社内勉強会など、会の目的や参加メンバーに応じて意識的に「伝え続けること」も大切な営みだと思っています。
人間はわからないことには距離を置いてしまいがちな生き物なので、データに纏わる解像度をあげるため、課題や面白さを伝えることも大切な対処法だと思っております(社内勉強会でのワイワイスレッド)
社外のプロフェッショナル人材の仲間を増やす
社内の限られたリソースだけで進めようと思うと、現実的にリソースの問題であったり、思うようにスピード感持って立ち上げが進まない困難もあります。
株式会社スマートバンクにおいても、専門のチームが存在しなかったため、兼務体制からの始まりでした。
課題に対処するため、データ活用のパートナーとして stable株式会社 にアドバイザーとして協力をしてもらっています。
Snowflakeの知見であったり、データモデリングなど、調査だけでも時間がかかります。限られた手札の中だけで進めると解決まで膨大な時間がかかることも。
スピード感を持って推進するために、ケイパビリティのある外部プロフェッショナルとコラボレーションするという戦略も1つの選択肢として良い意思決定でした。
雇用形態の違いはあれど、バーチャルチームとして進める仲間がいることで泥臭い作業も、前向きに取り組める効能もあるので、心理面でも課題を感じているデータ人材の方にはおすすめです。
さいごに
株式会社スマートバンクのデータ活用の障壁と、その課題に対処している現在地を紹介しました。 はじめは1人の兼務からはじまった営みでした。
世の中にはキラキラした事例も多いですが、実態は泥臭いことも多いです。
だけど 「組織がスケールするためには避けては通れない課題」で「組織全体へのレバレッジを効かせられる」といった大義や面白さも多くあります。
ときは、 AI時代 データを活用できる組織が勝つ!
ということで、引き続き同じ志を持つ同志の皆様、ともに頑張って参りましょう。

株式会社スマートバンクでは一緒に『ワンバンク』を創り上げていくメンバーを募集しています!カジュアル面談も受け付けていますので、お気軽にご応募ください 🙌