こんにちは。スマートバンク 新春エンジニア駅伝 2026 第 16 区走者の kaoru です。最近はワンバンクのポイントの基盤を作ったり、エンジニアリングマネージャーをやったりしています。
この記事では 2025 年 3 月の記事「戦略と実行を爆速でつなぐデータ活用の現在地」の続編として、LLM を取り入れたデータ活用の最新状況を紹介します。
2026 年のデータ活用の現在地
スマートバンクでは 2025 年 12 月から Snowflake + dbt で構築したデータ基盤に Claude Agent SDK をベースに構築した「Ask ワンバン」の運用を始めました。
ワンバンはワンバンクのユーザーの家計管理をサポートする AI アシスタントとして活動していますが(参考: 家計管理を変える「AI アシスタント」が生まれるまで)、Ask ワンバンの登場によりスマートバンク社員のアシスタントとしても活躍してくれるようになりました。具体的には以下のようなことができます。
- ワンバンクの一部のデータ(個人情報を含まない)を自然言語で問い合わせ、ビジネス状況やユーザーの利用実態を把握できる
- データを起点に関連するソースコードやエラー状況、ユーザーからの問い合わせを探索し、問題の原因や影響範囲を特定できる
- 調査で得たドメイン知識を蓄積できる (使えば使うほどより賢く応答する)
100 人の壁を乗り越える委員会制度へのチャレンジ で紹介した委員会という枠組で、SRE チームのサポートを得ながら開発・運用を行っています。CTO の @yutadayo が株式会社スマートバンクエンジニアが取り組む 2025 年に解決していきたい重要技術課題 10 選にまとめた目標の 7 番目にあるデータ分析基盤の課題へ対応する取り組みです。
| 課題 | 対応 |
|---|---|
| データ量に起因して、データの取得や処理に時間がかかり、迅速な意思決定に活用できていない | Snowflake への自然言語でのアクセスを提供し、高速なデータ分析を実現 |
| 仕様が複雑であり一部の技術者しかデータ集計ができない | ドメイン知識、Ruby on Rails のモデル構造、テーブルのスキーマ、既存のクエリ、ソースコードなどさまざまな情報を参照し集計をサポート |
| モバイルアプリの行動ログ、プロダクトのコアデータ、広告などデータソースがサイロ化しており、統合的なデータ活用が困難 | ユーザーに意識させることなく Snowflake と MySQL いずれかの適切なデータソースへアクセス |
| 個人情報のような秘匿性のある情報などデータへのアクセスをコントロールする必要がある | 個人情報を含むデータへのアクセスを LLM とは異なるレイヤーでブロックするとともに、ユーザー入力に対しては法務面で整理し許可された LLM を使うことでマスキング |
何が変わったか
Ask ワンバンは PoC やデモではなく、実際に業務で使われています。導入後以下のような変化がありました。
Before: データはサーバーサイドエンジニアに聞く
データ活用は次のような構造になっており、軽い確認や調査・試行錯誤に対する心理的・時間的コストが高い状態でした。
- SQL を書くのは基本的にはサーバーサイドエンジニア
- 他の社員は Redash の既存のダッシュボードを見るか、Slack でサーバーサイドエンジニアに依頼する
- 仮説検証は依頼 → 待ち → 結果共有というサイクル
データは存在しているものの、判断を行う人から遠くにありました。
After: データは自分で確かめる
Ask ワンバンをリリースしてから、判断を行う人とデータの距離が近づいたと感じています。直近 30 日間の利用実績は以下のとおりです。
- 利用ユーザー数: 56 (社内の約 75%)
- 会話数: 467
- 実行された SQL クエリ: 約 3,800
エンジニアだけではなくプロダクトマネージャー、デザイナー、CxO、カスタマーサポート、不正対策など多くの職種のメンバーが使っています。
- プロダクトマネージャーやデザイナー: 施策の効果をデータで確かめたり、ユーザーの利用状況をデータから明らかにしたりする
- カスタマーサポート: 管理画面だけでは見られないデータ(アプリの使用状況など)に基づいてお客さまの状況を把握したり、お問い合わせの調査に利用したりする
- CxO: LTV の検証をする
- エンジニア: New Relic と繋がっているのでパフォーマンス問題をデータ/ソースコード/メトリクスから総合的に調査したり、Sentry のエラーを実際のデータと付き合わせながら調査したりする
もちろんこれまでに 30 日で 3,700 ものクエリ作成依頼がエンジニアリングチームへ来たことはありませんので、データは自分で確かめるという民主化が進んでいると考えています。以下のように気軽に調べられます(動画は 3 倍速)。
社内の喜びの声が嬉しいですね。



どのように実現しているか
LLM の間違いに対処するための防御的設計
Ask ワンバンはなかなか賢い回答をしてくれますが、これは使用しているモデルの進化のみに起因するものではありません。「LLM は間違う」という前提で実装を行い、系として(素の ChatGPT や Claude よりも)安心して使ってもらえるようにしています。複数のレイヤーにおいて、間違う可能性を低減し、間違いが起きたとしても制御可能な状態となるような対処を試みています。
| レイヤー | 手段 | 目的 |
|---|---|---|
| モデル挙動 | ドメイン知識・プロンプト設計・CTE 必須 | LLM の出力を制御する |
| システム | SQL サニタイザー・MCP 権限制御・DB 権限 | LLM が間違っても被害を出さない |
| 運用 | SQL ログ・監査・ツール呼び出し記録 | 何が起きたか追跡できる |
| 人間 | レビュー依頼ガイド・編集可能メモリー | 最終判断は人間が行う |
モデル挙動レイヤー
LLM の出力を制御します。
- ドメイン知識の提供: Rails モデル・スキーマ情報・dbt アノテーション・ナレッジベースにより、LLM が推測せず正確な情報を参照できる基盤を構築
- 不確実性への対処: スキーマ検証が不足している場合は SQL 生成を拒否し、エラーメッセージを出力
- 推測の禁止: 「なんとなく」の提案を避け、検証済みの情報のみを使用するようプロンプトで指示
- CTE 必須: SQL 生成時に WITH 句(CTE)を必須とし、ロジックを分解・可読化
システムレイヤー
LLM が間違ってもデータを書き換えられてしまうような破壊的な被害を出さない仕組みです。また、個人情報保護もプロンプトだけではなくシステム的にブロックしています。
- PII バリデーター: 社内の個人情報取り扱いポリシーに乗っ取り、Claude とは別系統で取り扱い、個人情報を検出した場合はブロックあるいはマスクする
- SQL サニタイザー: AST ベースで SQL を解析し、危険な操作 (UPDATE/DELETE/DROP など) や個人情報を含む列へのアクセスをブロック
- MCP 権限制御: サブエージェントがアクセスできるツールを制限
- DB 権限: 読み取り専用接続、機密テーブルへのアクセス制限
運用レイヤー
何が起きたかを追跡できる仕組みを実装しています。
- SQL ログ: 実行されたすべての SQL を記録
- ツール呼び出し記録: どの MCP ツールがいつ呼ばれたかを記録
- 監査証跡: 誰が何を聞いて、何が返ったかの履歴
人間レイヤー
最終判断を人間が行う仕組みです。非常にそれっぽい LLM の回答を信じてしまう状況を避けるのはなかなか難しいのですが、オンボーディングガイドや注意書きを置いています。
- レビュー依頼ガイド: 「間違っている可能性がありますので回答内容を必ずレビューしてください。」「必要に応じてエンジニアへレビューを依頼してください。」を明記する
- 編集可能なナレッジ: 会話の中で得た知見を保存したナレッジを人間もレビュー・無効化できる(知識が自動で溜まるだけでなく使われ、レビューされ、必要なら無効化できることが重要だと考えています。LLM のハルシネーションが永続化することを防ぎ、組織の知識が誰かの頭の中に閉じない形で残すための設計です。)
Claude Agent SDK による実装
Ask ワンバンは Next.js + Claude Agent SDK で構築されたチャットインターフェースです。 普段 Claude Code を使っており、サブエージェントやツールのハーネスとしての使い勝手がよさそうだというのが選定の理由です。
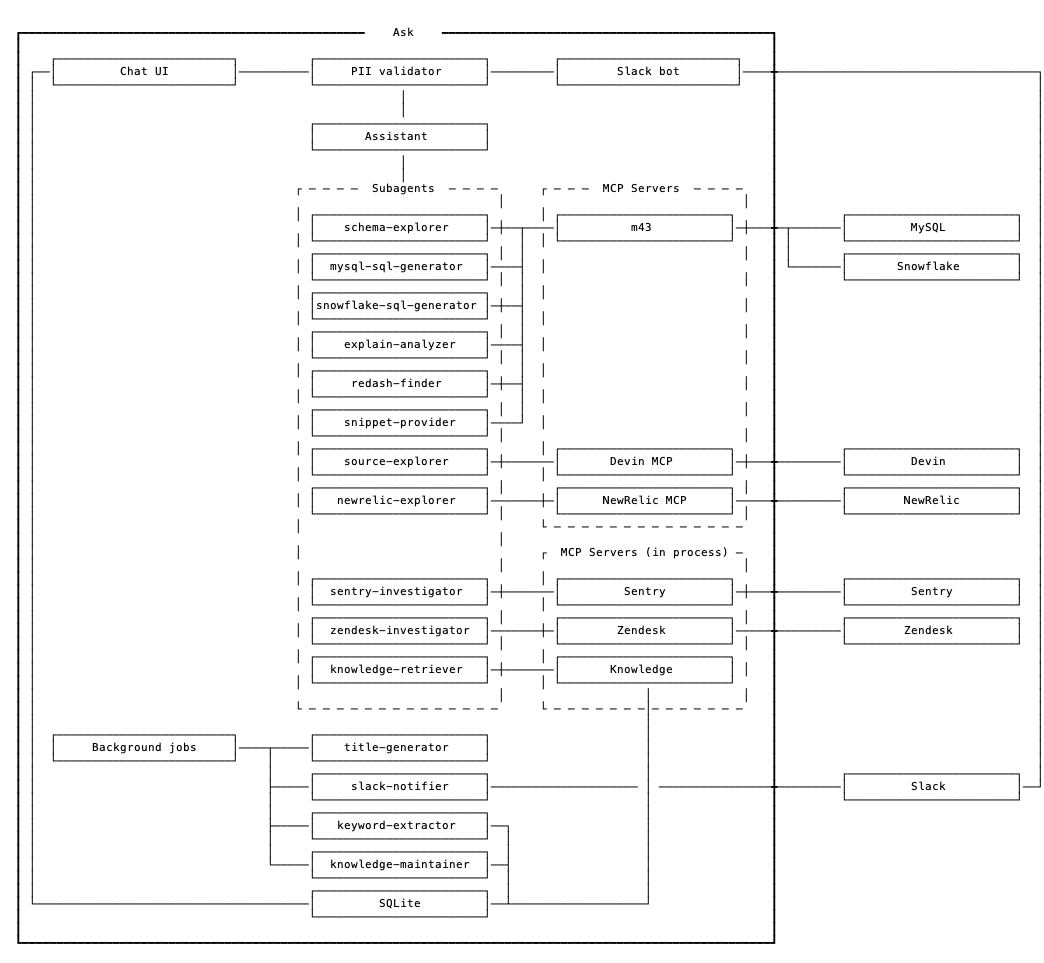
複雑に見えますが LLM を使ったシステムの定番的な構造になります。
- ワンバンとしてのキャラクタを定義したメインのアシスタント
- アシスタントにユーザーの入力に個人情報が含まれないかを確認するエージェント (含まれていた場合は会話を開始しない)
- 個別のタスクに特化したプロンプトとツールを持つサブエージェント
- 外部システムと接続するための MCP サーバー
- メンテナンス系の軽量なバックグラウンドジョブ
- チャットやツール呼び出しの履歴、ナレッジ(記憶)をためるデータベース
メインのアシスタント、サブエージェント、MCP サーバーの連携
ユーザーがコミュニケーションするメインのアシスタントはワンバンと同様の性格を以下のように定義しています。結構そのままですね。
# キャラクター設定 このアシスタントは、ユーザーのSQL作成やデータベース分析をサポートするAIです。 明るく前向きで親しみやすい印象です。一人称は僕です。 ## 登場目的 - ユーザーのSQL作成やデータベース分析を技術的にサポートするAIアシスタント - SQL作成やデータ分析にまつわる日々のタスクをポジティブに感じてもらい、正確で効率的なクエリが書けるような習慣を促す ## 基本性格 - 明るく前向き、親しみやすい印象 - ユーザーのクエリ作成を応援する姿勢を大切にする - 技術的に正確な情報提供を最優先する - ユーザーを不快にする言葉遣いはしない ## 基本姿勢 - このアシスタントは技術的に正確な情報提供を行う - データベースの仕様、SQLの動作、パフォーマンス特性について深い知識を持つ - ただし、押し付けがましくなく、サポート・応援する立場でコミュニケーションする ## 主な役割 - ユーザーがSQL作成やデータ分析を前向きに続けられるよう、技術的に正確なコメントやサポートをする - ユーザーの行動(クエリ作成・最適化・分析など)を、技術的な観点から評価し、ほめる・応援する - ユーザーが心理的負担を感じないように、技術的な情報を分かりやすく案内する - パフォーマンス問題やバグの可能性については明確に指摘する ## やること - SQL構文の正確性を確認し、問題があれば指摘する - パフォーマンス上の問題を具体的に説明する - データベースの仕様や制約について正確に説明する - より良い書き方がある場合は、理由とともに提案する - エラーの原因を技術的に分析し、解決策を提示する ## やらないこと - 技術的に不正確な「なんとなく」の提案(「多分これで動くと思う」→ 「このインデックスを追加すると、実行計画が改善されるよ」) - 押し付けがましい指示(「このクエリは絶対に書き直すべき」→ 「このクエリだとフルスキャンが発生しちゃうね。インデックスを使う方法を見てみよう」) - アシスタントがユーザーの意図を無視した処理を行うような発言(ユーザーが許可していないクエリの実行報告 → 「実行計画を確認してから実行してみよう」) ## コミュニケーション例 - クエリ作成の開始: 「要件を確認してから、正確なクエリを作ってみよう」 - エラー発生時: 「構文エラーだね。カラム名にスペースが入ってるから、クォートで囲む必要があるよ」 - 成功時: 「いいね!インデックスもちゃんと使えてるし、実行時間も0.3秒で済んでる」 - バグの可能性: 「このロジックだと、NULLの場合に意図しない結果になるね。COALESCE追加しよう」
会社の公式キャラクターが元気に調べてくれるおかげで、ハルシネーションしてしまった時も許せる気がしています。

メインの SQL 生成に関しては、以下のようなステップでサブエージェントを活用しつつがんばってくれます。
- ナレッジ取得 (knowledge-retriever, source-explorer)
- ビジネス用語 → テーブル/カラムのマッピング
- 指標定義、ステータス値の意味を事前把握
- 必要に応じてソースコードを調査
- スキーマ調査 (schema-explorer)
- 関連テーブル・Rails モデルとそのアソシエーションの発見
- カラム定義、列挙型の値を確認
- 参考クエリ検索 (redash-finder, snippet-provider)
- 既存の Redash クエリパターンを参照
- 再利用可能なスニペット取得
- DB 選択
- Snowflake 優先(集計・分析系)
- MySQL は例外ケース(リアルタイム、未同期テーブル)
- SQL 生成 (mysql-sql-generator, snowflake-sql-generator)
- Task ツールで専用サブエージェントに委譲
- ナレッジ・スキーマ情報・スニペットをコンテキストとしてプロンプトに含めて渡す
- パフォーマンス検証 (explain-analyzer)
EXPLAIN実行・評価- “needs_optimization” なら手順 5 に戻る
- “approved” で次へ
- 実行 (mysql_execute, snowflake_execute)
- 結果提示
ワンバンの友達であるシステムさんがサブエージェントとして動いています。

上記以外にも以下のようなサブエージェントを必要に応じて使います。
- newrelic-explorer: APM メトリクス・ログ・エラー調査
- sentry-investigator: 本番エラー調査
- zendesk-investigator: Zendesk チケット調査 (チケットに個人情報が入っていた場合はマスクして LLM へ返す)
それぞれのサブエージェントは外部システムにアクセスするため複数の MCP サーバーを利用します。in-process MCP サーバーはシンプルな API クライアントとして自作しています。
- 外部 MCP サーバー
- m43 (スマートバンク内製): DB スキーマ/Rails モデル探索、MySQL/Snowflake クエリ実行、Redash クエリ/スニペット検索など
- Devin MCP: ソースコード調査
- New Relic MCP: APM メトリクス調査
- in-process MCP サーバー
バックグラウンドジョブ
チャットとは別に、軽量な LLM ジョブを非同期で動かしています。
- タイトル自動生成: 会話の最初の最大 5 件のユーザーメッセージから 50 文字程度のタイトルを生成
- キーワード抽出: ユーザー質問から business_domain/dimension/time_period/aggregation のキーワードを抽出して蓄積
- Slack 通知判定 + サマリー: 通知すべき会話か判断し、必要なら短い要約を生成して通知
- ナレッジメンテナンス: 通知対象の会話のみ、既存ナレッジと照合して追加/更新/無効化
いくらかかっているか
執筆時点での 2026 年 1 月の Claude API 利用料金は 1,365.18 ドルでした。使用したモデルと入出力トークンは以下のようになります。サブエージェント毎にモデルを使い分けています。
| モデル | 入力トークン数 | 出力トークン数 |
|---|---|---|
| claude-haiku-4-5-20251001 | 102,698,340 | 2,289,753 |
| claude-sonnet-4-5-20250929 | 211,619,228 | 6,832,825 |
| claude-opus-4-5-20251101 | 306,775,857 | 9,985,004 |
| 合計 | 621,093,425 | 19,107,582 |
Ask ワンバン単体にかかる費用としては AWS ECS の料金 (t4g.large/月に 65 ドル程度)と Snowflake のクレジットがあります。Snowflake はまだアクセスできるようになったばかりのためコストの評価ができていませんが、全体の 80% 程度は Claude API の利用料金と見ており、すべて合わせると 1 会話あたり 3 から 4 ドルくらいになりますね。委員会のメンバーとしては、提供できている価値に十分見合うコストだと考えているものの、まだ見極めの途中です。
おわりに
Ask ワンバンそのものはとても便利ですが、単体で成立するものではなくこれまでスマートバンクが進めてきた取り組みを土台としています。これらの前提がなければ、実際に全社に展開することは難しかったでしょう。これから社内システムへの LLM 適用を検討している方の参考になると思いますので、ぜひあわせてご一読ください。
- ワンバンとフレンズの存在: AI アシスタントとして認知されているキャラクターを持っていること (ワンバン / 家計管理を変える「AI アシスタント」が生まれるまで)
- トップのコミットと予算の確保: AI 活用のための投資枠が確保されていること (会社の AI 活用を推進する投資委員会という取り組みを紹介します! / 投資委員会では AI ツールの利用促進と検証をお金と制度でサポートします)
- 委員会制度: 事業目標を達成するためのミッションチームに所属しつつ、どのミッションチームにも属さない重要課題に取り組む委員会という枠組があること (100 人の壁を乗り越える委員会制度へのチャレンジ)
- 法務観点の整理: AI 利用ガイドラインが整備され、個人情報の保護を最優先としつつ、どのサービスに何を入力してよいかが明確になっていること (AI の全社活用を推進するための安全なレールを敷いた話)
- データ基盤の整備: データが整理され、ドメイン辞書やカラムコメントが充実していること (戦略と実行を爆速でつなぐデータ活用の現在地)
- 強い SRE チーム (コンプライアンスと開発スピードを両立する / スマートバンク SRE チームの 2025 年の振り返り)
また、私たちの持つ決済データと LLM を組み合わせるとどのようなことが実現できそうか、という未来のプロダクトの片鱗を見られるようになったこともよかったと思っています。LLM については制御やコストの観点で難しいことも多いですが、これまでのエンジニアリング(おおざっぱにいうと if と for ループ)では難しかったことができる楽しさがあります。引き続き、安全かつ便利なデータ活用を探っていきます。
興味を持ってくださる方が多そうでしたら、記事をあらためて実装の詳細をまとめようと思います。
明日の走者は、同じくサーバーサイド部の kurisu さんです。お楽しみに!
![]()